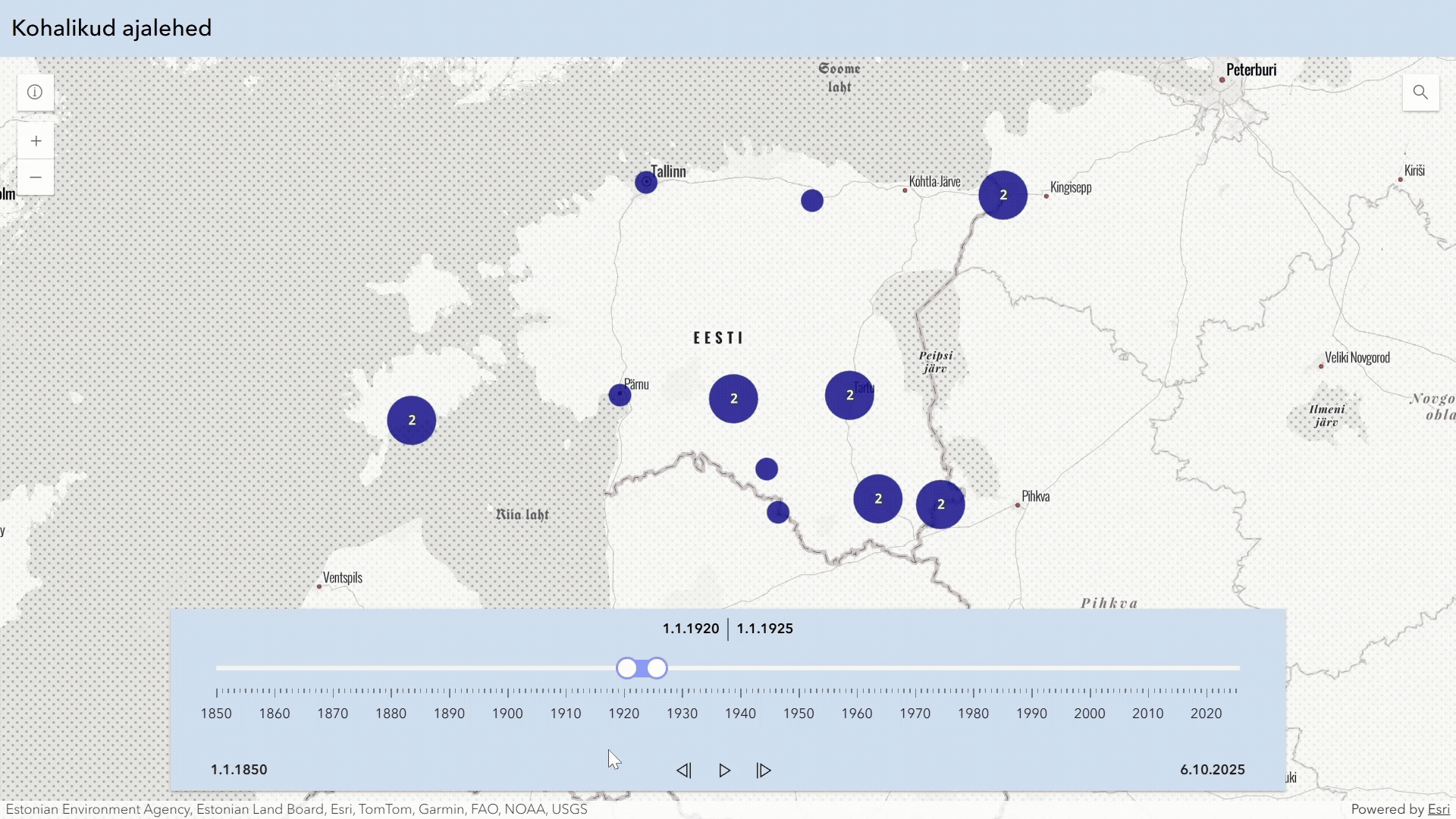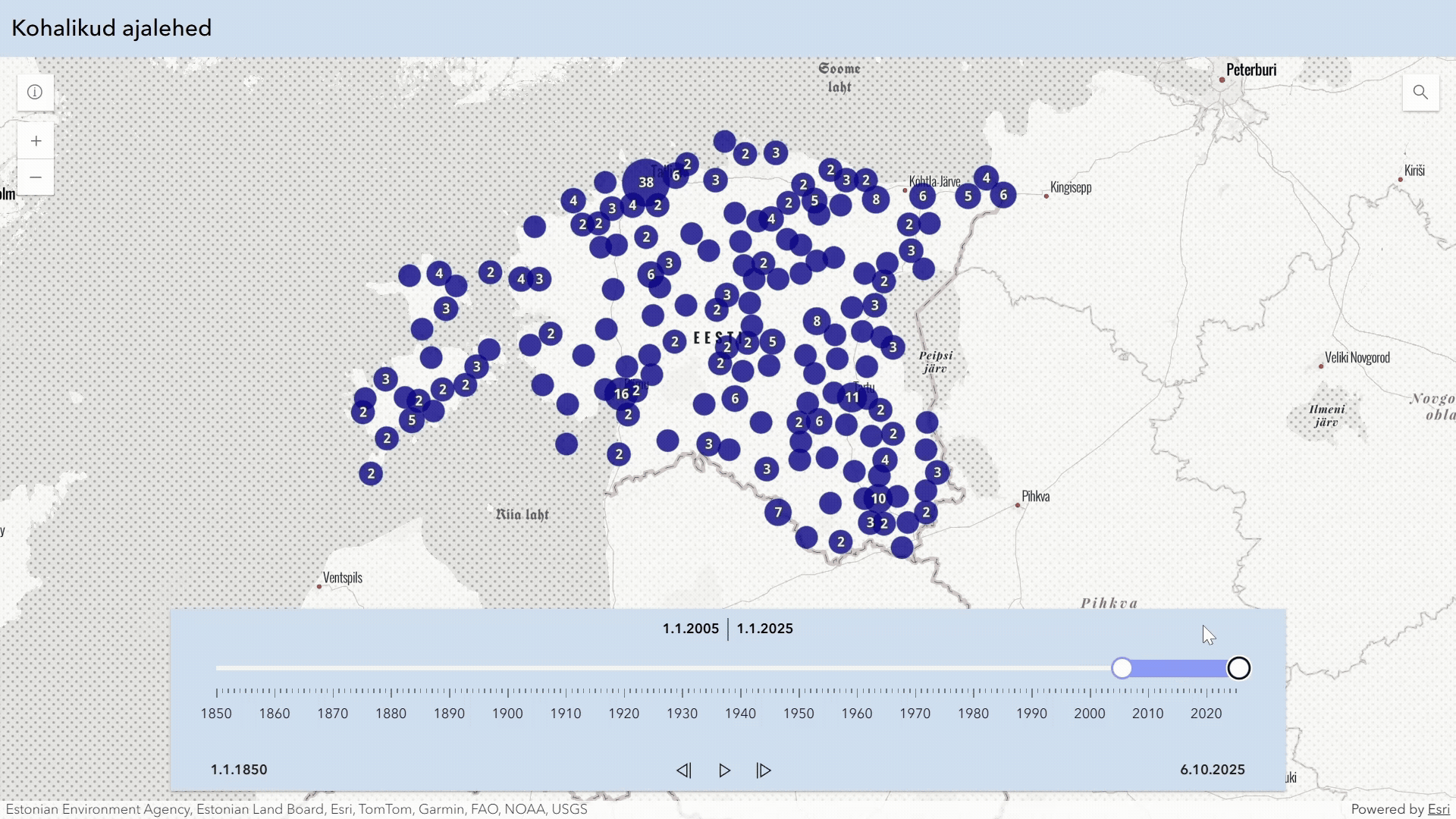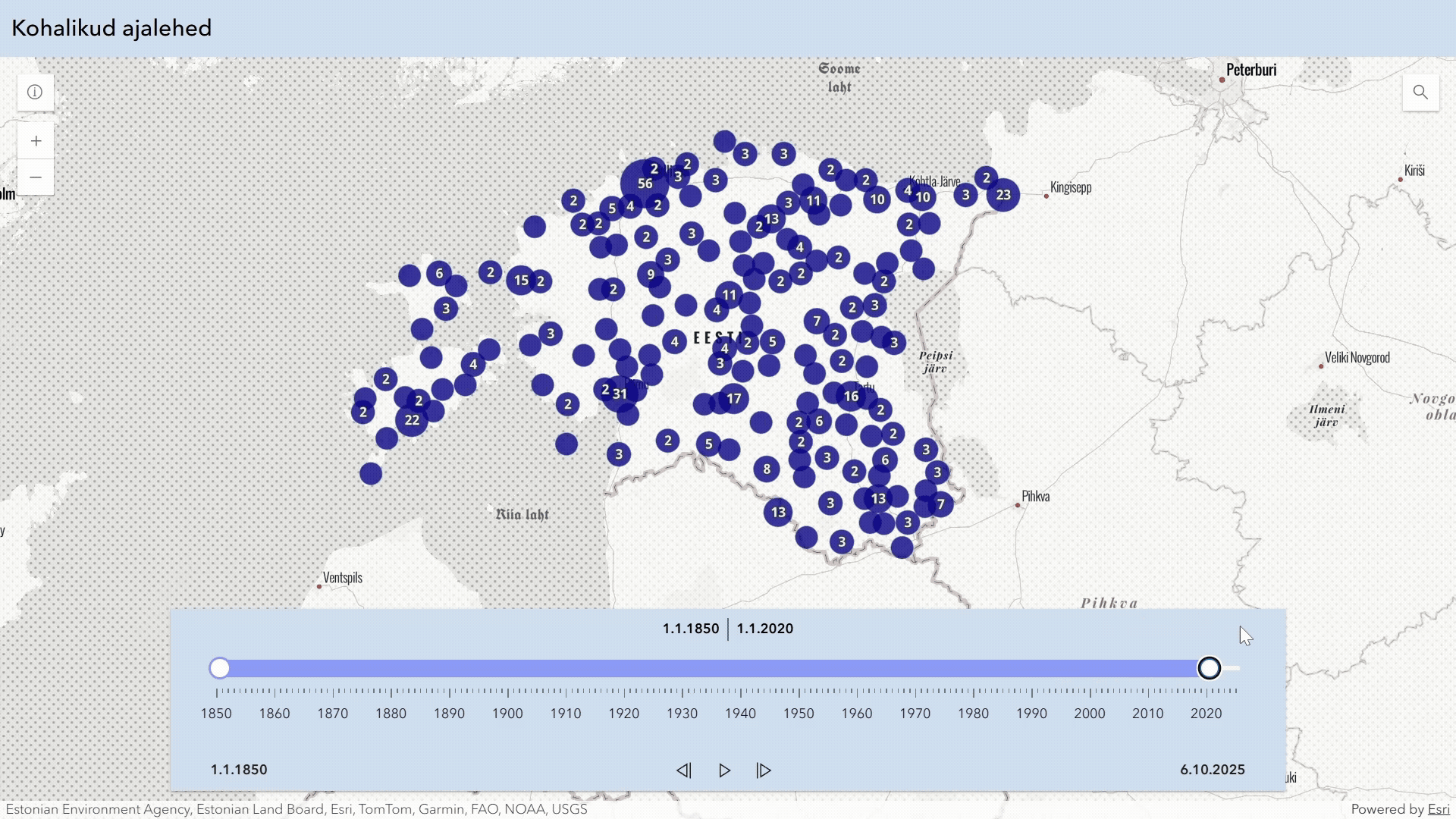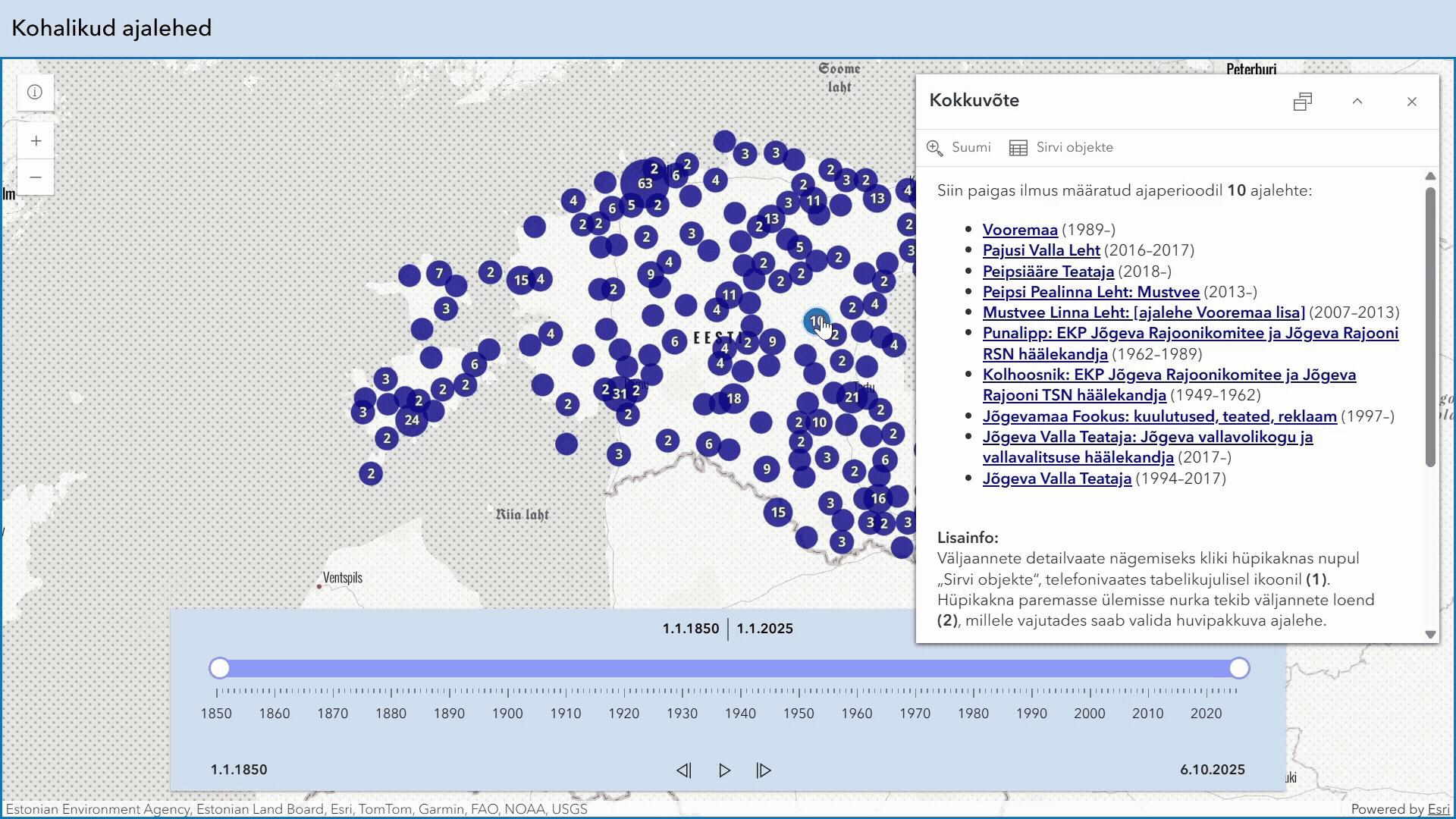
Eesti kohalike ajalehtede ilmumispaiku visualiseeriv kaardirakendus.
Vaata veel
Rakendus on eraldiseisvana leitav veebilehel: https://nlib.maps.arcgis.com/apps/instant/slider/index.html?appid=90861a54976641978c54a6c3213aa7a0
Abi lehekülg on täiendamisel.
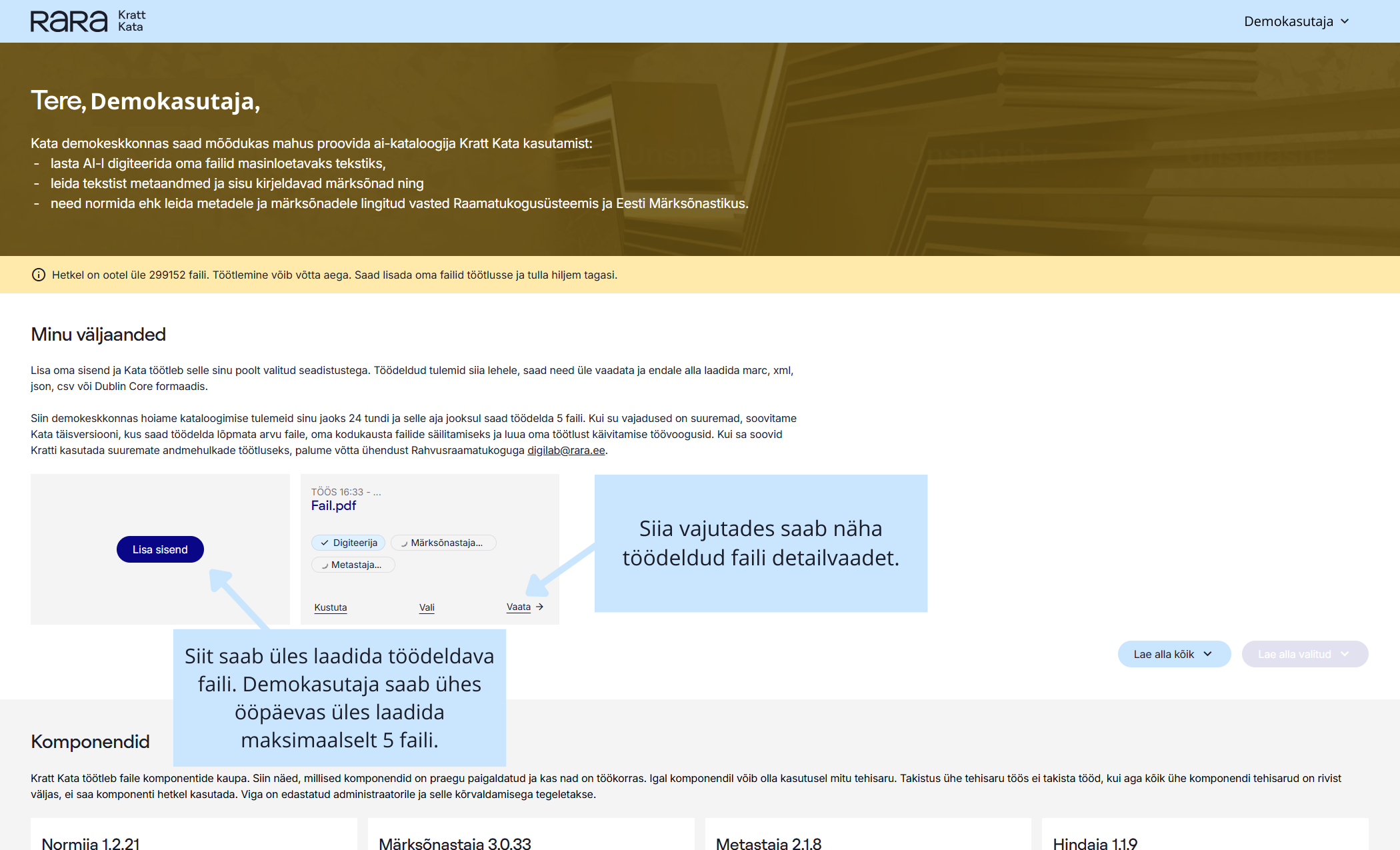
Failide lisamine rakendusse
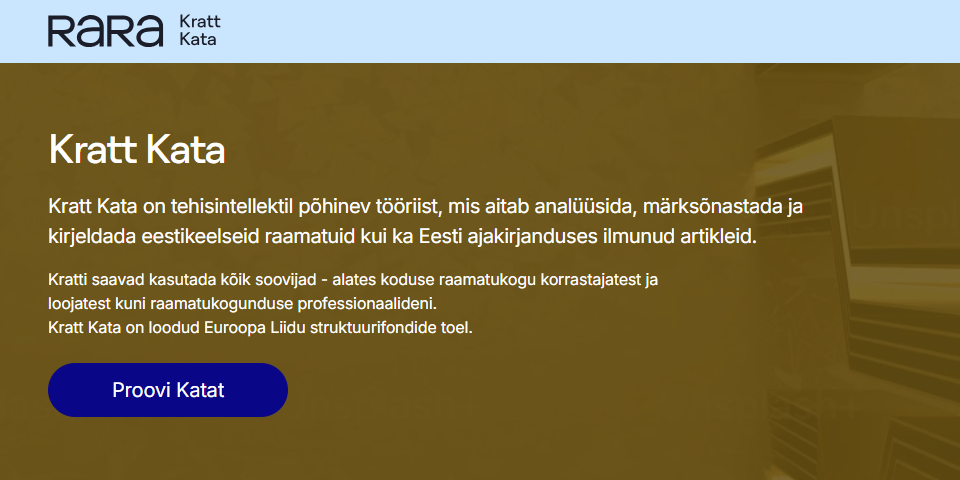
Kratt Kata toetab järgmisi failiformaate: .epub, .pdf, .txt, .html, .jpg/.jpeg, .png, .doc, .docx. Masslisamisel on toetatud ka METS/ALTO failiformaat.
Kuigi üles laaditud faile krati treenimiseks ei kasutata, palume mitte üles laadida enda või teiste isikuandmeid sisaldavaid faile.
Ei, teised kasutajad üleslaaditud faile ei näe. Suuremate õigustega kasutajad näevad failide nimesid, kuid mitte sisu. Üles laaditud faile säilitatakse 24 tundi, misjärel need kustutatakse.
Kratt Kata sujuva toimimise tagamiseks on piiratud demokasutajate failide üleslaadimise maht. Demokasutajad saavad 24 tunni jooksul krati abil töödelda kuni viit faili.
Veebilehe aadress peab viitama veebis olevale konkreetsele failile ehk URL-i lõpus peab alati olema rakenduses toetatud failiformaadi tunnus (näiteks .pdf).
Tööriista toimimine
Kratt Kata on tänase seisuga treenitud arvestades vaid säilituseksemplaride sisu. Tegemist on tööriista esimese versiooniga, mida RaRa jooksvalt täiendab, parendab ja treenib.
Teenusetingimuste lehekülg on loomisel.
Aastate jooksul on ühisloome käigus parandatud DEA portaalis olevate perioodikaväljaannete tekstituvastust, millest on valim näiteid koondatud andmestikuks OCR tekstiparandused. Lisaks tekstiparandustele sisaldab andmestik ka parandusele eelnenud teksti ja GPT-4o mini hinnangut teksti kvaliteedile.
Andmestikku parandasid ja täiustasid TalTechi tudengid Loore Lehtmets ja Mari-Anna Meimer bakalaureusetöös „Ajalooliste eestikeelsete OCR tekstide järeltöötluse ja hindamise automatiseerimine Eesti Rahvusraamatukogu jaoks“. Töö eesmärgiks oli välja töötada lahendused ajalooliste tekstide kvaliteedi hindamiseks ja parandamiseks. Bakalaureusetöö raames valmis neli vabavaralist keelemudelit, millest kaks hindavad tekstide kvaliteeti ja kaks parandavad teksti. Mudelid on treenitud eestikeelse Llammas keelemudeli baasil. Töö käigus katsetati mitmeid meetodeid (näiteks eelistuste suunamine ja preemiamudeli metoodika) ning tulemusi võrreldi ka teiste keelemudelitega, näiteks ChatGPT-4o ja DeepSeek V3.
Bakalaureusetöö käigus valminud mudelid (kasutusjuhendid mudelite README-des):
Bakalaureusetöö GitHub-i repositoorium: https://github.com/mari-annam/estonian-ocr, sealhulgas:
Bakalaureusetöö Hugging Face repositoorium: https://huggingface.co/mariannam.
Rakendus on eraldiseisvana leitav veebilehel: https://data.digar.ee/netl/
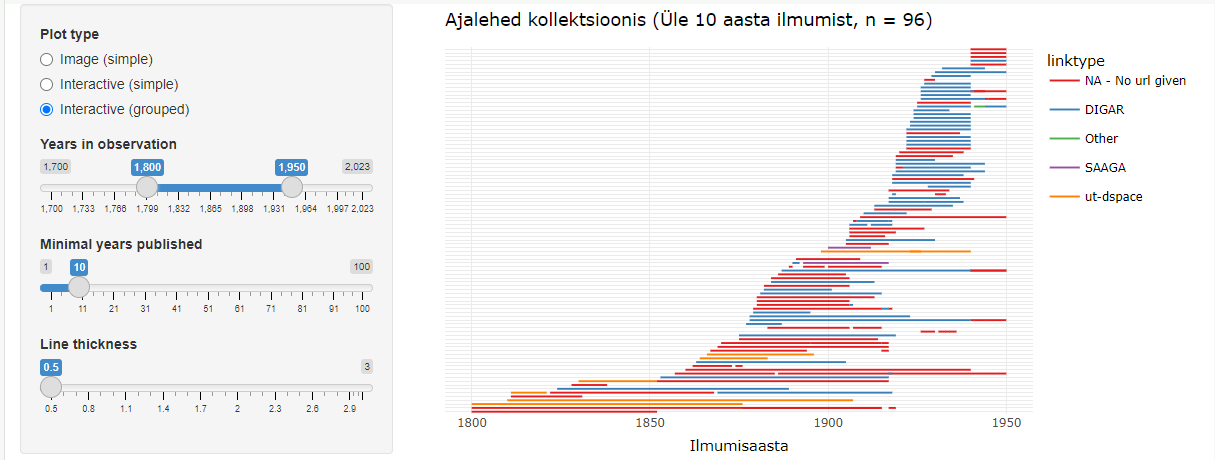
Eesti kultuuripärandist on digiteeritud hulk ajalehti, aga kaugeltki mitte kõik. Seda informatsiooni on osaliselt kajastatud ERB perioodika andmekogus. Siin on loodud visuaalne vahend sellest ülevaate saamiseks.
Rakendus on eraldiseisvana leitav veebilehel: https://digilab.shinyapps.io/digitized_newspapers/
Digiteeritud ajalehed Eestis annab visuaalse ülevaate ajalehtede digiteerimise seisust Eestis. Andmed pärinevad ERB perioodika osast. Viimase paari aasta jooksul digiteeritud ajalehed ei ole veel kõik selliseks märgitud.
Visuaalne vahend võimaldab valida teatud ajaperioodi (alguses 1800–1950) ning sealt alt lehti, mis on ilmunud vähemalt kindlal hulgal aastaarvudest (alguses 10). Neid parameetreid saab muuta liigutades jooni rakenduse vasakul äärel.
Lisaks on võimalik muuta joone paksust, kuna eri parameetritega võib kujutatud ajalehtede hulk muutuda oluliselt. Kui algselt on kuvatud alla 100 ajalehe, siis kõiki eri väljaandeid kuvades võib joonistada üle 1200 joone.
Joonisel kuvatakse ajalehti lihtkujul (simple) või grupeeritult (grouped). Grupeeritud versioon paigutab lehti, mida saab pidada eelmiste jätkuks ühele joonele.
Graafik võib olla interaktiivne (interactive) või lihtpilt (image). Interaktiivsel graafikul saab lehtede kohta rohkem informatsiooni liigutades hiirt joonte peal. Menüü ülaribal olevate nuppude või graafiku piirkonna valimise abil on võimalik graafiku mõnda kohta lähemalt vaadata. Lisaks on võimalik digiteeritud ajalehtede joontele klikkida, mis viib neid majutava digikollektsiooni kodulehele ja selle ajalehe kogule seal, juhul kui see on võimalik.
Märkus
Tööriista valmimist on toetanud teadusprojekt EKKD72 "Tekstiainese kasutusvõimalused digihumanitaaria juhtumiuuringutes Eesti ajalehekollektsioonide (1850-2020) näitel".
Andmed on viimati uuendatud aprill 2023. Andmed ja kood on ligipääsetav OSF-is https://doi.org/10.17605/OSF.IO/B2HPX.
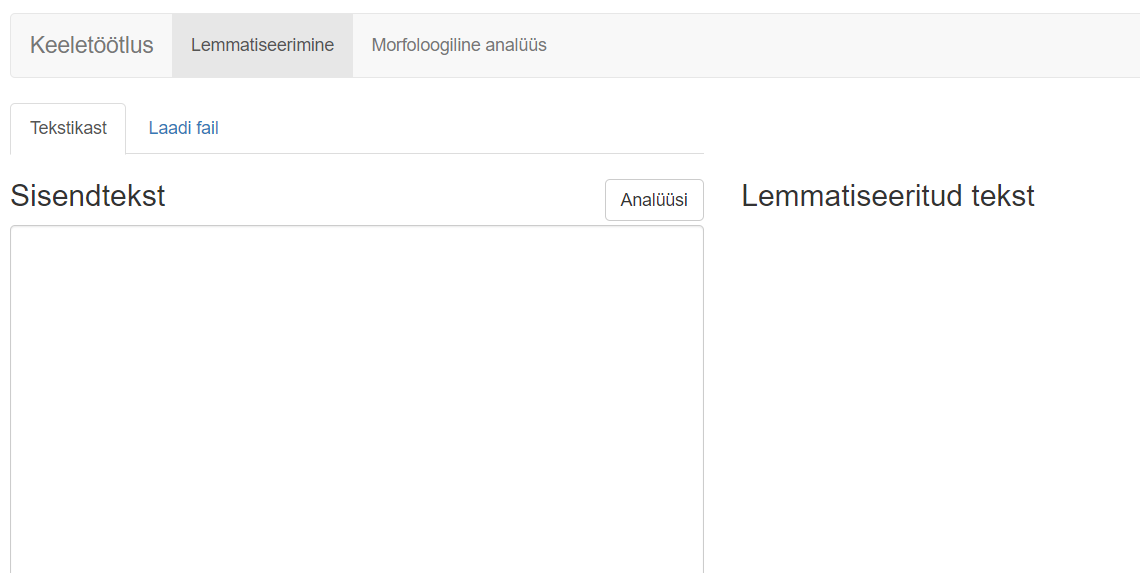
Uku Raudvere ja Kristel Uiboaia loodud keeletöötlustööriist võimaldab sissetrükitavat või failina üleslaaditavat teksti lemmatiseerida ning morfoloogiliselt analüüsida.
Lemmatiseerimine on sõnade algvormi kujule muutmine – eesti keeles on tekstisiseselt paljud sõnad käändes, mis teeb teksti analüüsi keeruliseks, kuid lemmatiseerimisega on võimalik sõnu standardiseerida.
Morfoloogiline analüüs näitab, milline on sõna vorm, nt sõnaliik, kääne või pööre ning arvuline väärtus (ainsus või mitmus). Tööriist esitab väljundi CSV-failina.
Tööriist on leitav veebilehelt https://tekstianalyys.utlib.ut.ee/index.html#.

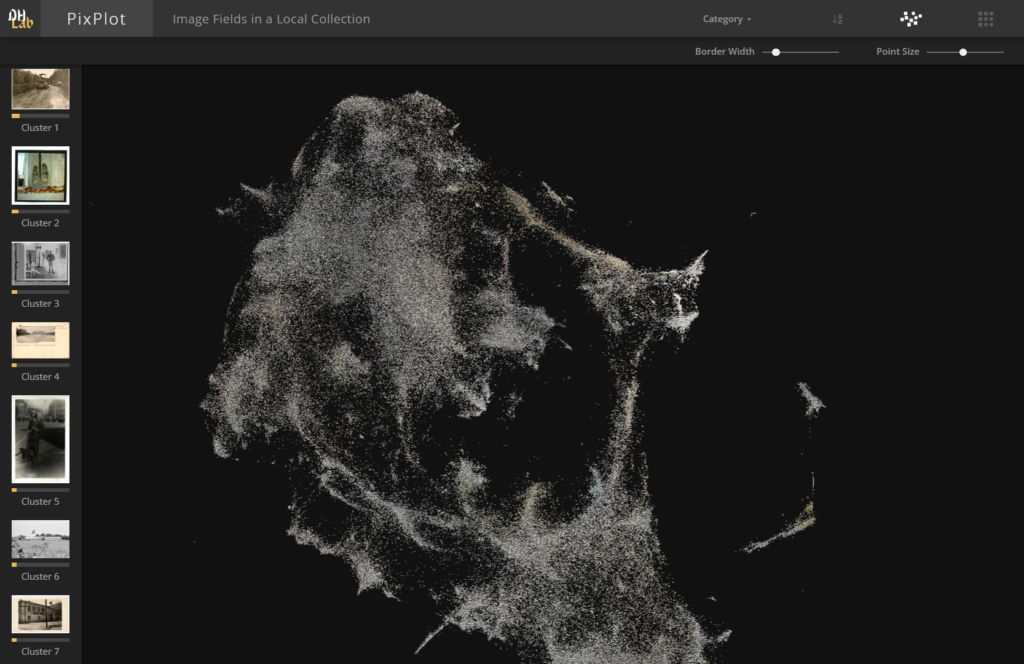
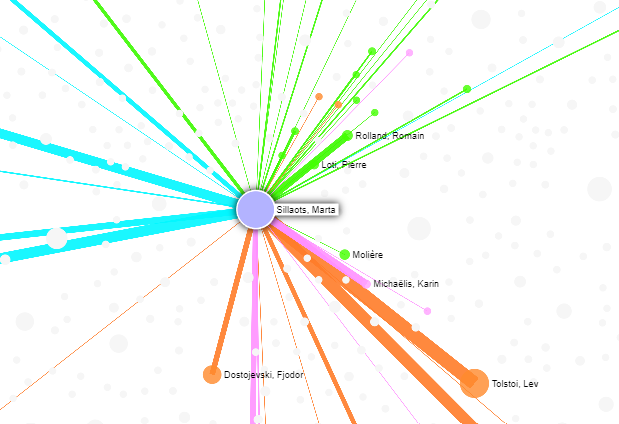
Muinsuskaitseameti kratt Folli on loodud selleks, et tehisintellekti abil muuseumite kogudes leiduvat visuaalset materjali automaatselt kirjeldada ja süstematiseerida. Üks oluline ja ajamahukas osa piltide kirjeldamisest on seal leiduvate objektide nimetamine. Folli aga suudab automaatselt fotodelt näiteks inimesi, maju, mööblit ja muid objekte leida. See omakorda parandab otsinuguvõimalusi ja võimaldab teha detailsemaid analüüse kogude sisu kohta.
Üks osa Folli arendamisest on demorakendus, mis visualiseerib enam kui 250 000 fotost koguneva pildikuju visuaalse sarnasuse alusel. Sarnase sisuga fotod asetsevad fotopilves üksteisele lähemal, moodustades niimoodi visuaalsete teemade põhjal klastreid. Näiteks võib pilve ühest osast leida nõukogudeaegsed fotod sünnipäevapidusest, teises kohas jälle pildid Tallinna kohal tiirutavast tsepeliinist jne.
Demorakenduse leiad siit: http://folli.stacc.cloud/demo
(rakendus võib käivitamiseks paar minutit aega võtta)
Folli kasutab piltide võrdlemiseks numbrilist vektorkuju. Piltide töötlemisel on kasutatud tehisnärvivõrku InceptionV3 ja dimensioonide vähendamise algoritmi UMAP. Demorakenduse kasutuseliides kasutab lõplikuks visualisatsiooniks Yale'i ülikoolis välja töötatud lahendust PixPlot.
Krati tehnilise teostuse eest vastutab STACC OÜ. Töö on tellinud Muinsuskaitseamet koostöös Rahvusraamatukoguga ja projekti rahastati Euroopa Liidu Regionaalarengu Fondist.
Selle Pythoni mooduliga on võimalik DIGAR (Rahvusraamatukogu Digiarhiivi) ja ERB (Eesti Rahvusbibliograafia) metaandmete kollektsioone soovi korral ise alla laadida. Samuti on moodulis funktsioonid nende teisendamiseks XMList TSV ja JSON formaatidesse.
Moodul koos paigaldus- ja kasutusjuhendiga asub siin: https://github.com/RaRa-digiLab/metadata-handler
Kuna andmestikud on kättesaadavad ka meie andmestike lehel, on moodul eelkõige sobiv automatiseeritud lahendusteks ja muudeks katsetusteks.
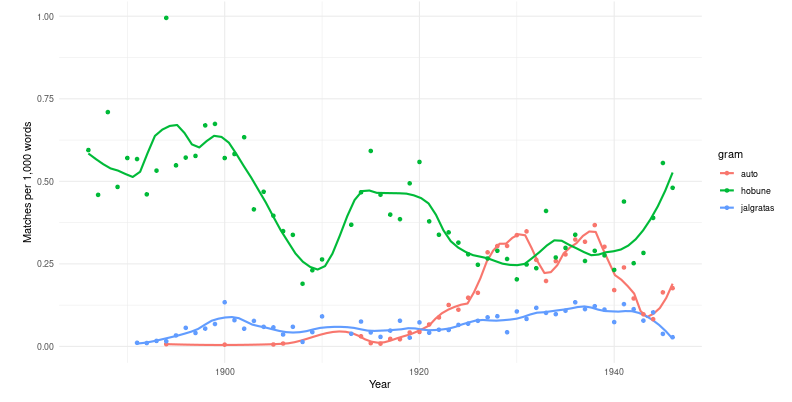
Rakendus on eraldiseisvana leitav veebilehel: https://digilab.shinyapps.io/dea_ngrams/
Tööriist võimaldab kuvada sõnade ja sõnamitmike sagedust läbi aja - st kui levinud oli mõni termin või fraas tekstikogus. Sõnamitmikeks ehk n-grammideks nimetatakse üksteise kõrval olevate sõnade kooslusi. Tekstikogu sisaldab endas 39 ajalehte 1850-2023 ja annab suhteliselt hea ülevaate Eesti meediaruumist selle aja vältel. Täpsemalt vaata sisu dokumentatsioonist.
Tööriista kasutamiseks tuleb sisestada otsingusõna. Selle saab sisestada otsingukasti vasakul üleval. Mitmesõnalise otsingu tegemiseks kasutage tühikut, mitme erineva otsingu tegemiseks reavahetusklahvi ENTER (töötavad ka TAB ja koma). Otsida saab korraga kuni kaheksat mitmikku, mis koosnevad kuni kolmest sõnast.
Näiteks on võimalik otsida seal korraga sõna terevisioon ja sõnaühendit aktuaalne kaamera ilm. Otsingulahtri all saab valida, kas otsingut teostatakse muutmata tekstide peal, kus käänded ja pöörded on olemas või sõnade algvormide ehk lemmade seast. Esimese valiku puhul on võimalik leida sõnu on ja oli, kuid lemmatiseeritud tekstide puhul vaid sõna olema. Mitmesõnalise ühendi juures eralda sõnad tühikuga.
Otsingu tulemused kuvatakse paremale äärde. Kui graafik on tühi, siis otsitud sõna või sõnaühendit ei leitud. Vasakult saab muuta ka vaadeldavat ajaperioodi ning graafiku joone kõverust.
Graafikul kujutatakse otsinguterminite sagedust tuhande sõna kohta. Selline kuvamisviis aitab arvestada tekstikogu suuruse muutustega.
Graafiku all on leitav tabel kõigi analüüsiks kriitilise piiri ületanud sõnade ja sõnaühenditega. Seda tabelit saab kasutada otsingusõnade leidmiseks. Tabelis on võimalik kasutada otsinguteks ka regulaaravaldisi. Tabelis tehtud otsingud ei mõjuta joonist.
Rakendus võtab tavaliselt 10-15 sekundit, et laadida. Kui näete paremal all tabelit sagedate sõnadega, on rakendus käivitunud ja saate otsinguid teha.
Andmed
Tööriistas on koondatud suuremad lehed Rahvusraamatukogu kollektsioonidest. Valitud on Eestis ilmunud päevalehed ja kohalikud lehed, millel on olemas vähemalt viis digiteeritud aastakäiku. Kokku on neid 39 erinevat väljaannet. Täpsema ülevaate saab jooniselt all.
Töötlus
Digiteeritud materjalides on tihti vigu tähtede tuvastamisel. Mõned tähed on valesti loetud, mõned sõnad jaotatud tükkideks või mõned varjud paberil loetud sõnadeks. Selle jaoks, et vältida nende vigade mõju tulemustele, on analüüsidest jäetud kõrvale kõik sõnalaadsed üksused, mis sisaldavad endas ainult ühte tähte. Kõrvale on jäetud ka tähemärgid, mis ei ole tavaliselt eesti sõnades (sh nt jutumärgid, sidekriipsud, punktid, komad jne). Kõik suured tähed on muudetud väikesteks.
Sõnade ja sõnamitmike kokkuloendamisel on jäetud kõrvale haruldased sõnad, mille puhul sageduste analüüs ei ole mõistlik. Täpsemalt on jäetud kõrvale sõnad ja sõnamitmikud, mida esineb vähem kui 40 korda ühe kollektsiooni sees ja vähem kui 1000 korda kõigi kollektsioonide peale.
Lemmatiseerimisel on kasutatud EstNLTK (v 1.4.1) Pythoni teegi lemmatiseerimise vahendeid Vabamorf jt.
Ülevaade andmestikust
Hiirt punktide peal liigutades näeb lisainformatsiooni, väljaande täisnime andmebaasis, mitu numbrit sel aastal on ilmunud jne. Kuna joonisel on kokku pandud mitu eriliigilist andmestikku, pole igal lehel täit informatsiooni, ära on toodud see, mis oli kättesaadav.
Märkus
Tööriista valmimist on toetanud teadusprojekt EKKD72 "Tekstiainese kasutusvõimalused digihumanitaaria juhtumiuuringutes Eesti ajalehekollektsioonide (1850-2020) näitel". Tööriista arendab Rahvusraamatukogu digilabor.
Andmed on viimati uuendatud august 2023. Andmed ja kood on ligipääsetav OSF-is https://doi.org/10.17605/OSF.IO/XHU2A.
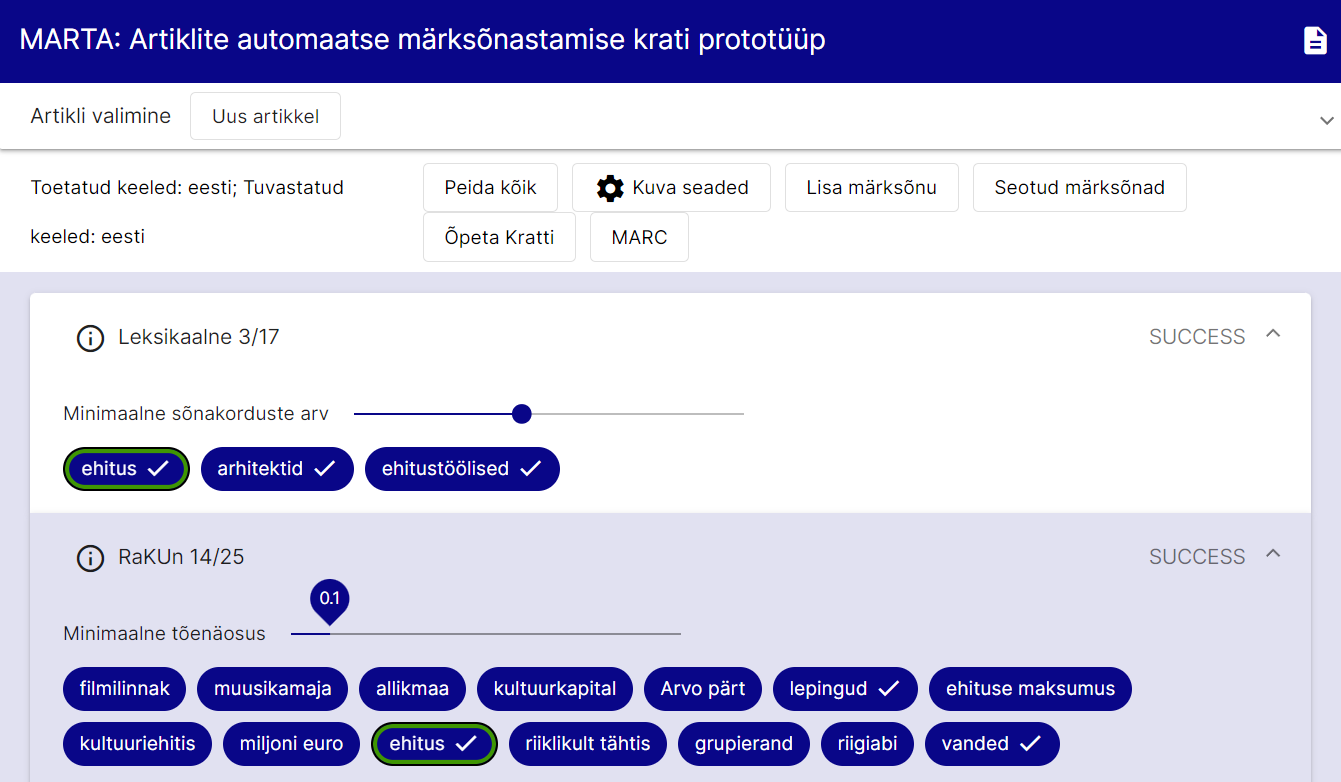
Hetkel kratt MARTA ei tööta. Tegeleme probleemi lahendamisega.
Krati leiad siit: https://marta.nlib.ee
MARTA näol on tegu eestikeelsete artiklite automaatse märksõnastamise krati prototüübiga. Prototüüp võtab sisendiks teksti (kas tavatekstina, laeb selle alla etteantud URLilt või eraldab üleslaetud failist), soovi korral võib kasutaja valida rakendatavad metoodikad ja/või artikli valdkonnad. Järgmise sammuna tekst lemmatiseeritakse ning eraldatakse sõnaliigid (part-of-speech tags), kasutades Texta Toolkiti tööriista MLP10 (multilingual preprocessor). Pärast lemmatiseerimist rakendatakse märksõnastamismeetodeid, mis eraldavad tekstist järgmised märksõnad:
Leitud märksõnu võrreldakse Eesti Märksõnastikuga (EMS) – kui leitud märksõna esineb ka EMSis, kuvatakse selle taha linnuke. Tuvastatud märksõnu on rakendusest võimalik MARC formaadis eksportida.
Prototüübi täpsema kasutusjuhendi leiad siit.

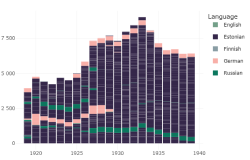
Andmetega töötamisel on vaja omada head ülevaadet enda andmestikust: millistest allikatest pärinevad andmed, kuidas on neid töödeldud ja milles neid usaldada tasub, milles mitte. Konkreetsete analüüside puhul tasub ehitada uuritav andmestik selliseks, et ta klapib uurimistöö eesmärkidega ja analüüsivahenditega.
Ülevaate saamise hõlbustamiseks on digilaboril abiks DEA (Digiteeritud Eesti Artiklite) metaandmete sirvija. See on visuaalne keskkond andmestiku sisust ülevaate saamiseks. Metaandmete sirvija töötab ligipääsetavast kollektsioonist välja võetud metainfoga. JupyterHub keskkonnas saab samale metainfole ligi järgmise käsuga.
all_issues <- get_digar_overview()Rakendus on ligipääsetav ka eraldi Shiny keskkonnas.
Märkus
Tööriista valmimist on toetanud teadusprojekt EKKD72 "Tekstiainese kasutusvõimalused digihumanitaaria juhtumiuuringutes Eesti ajalehekollektsioonide (1850-2020) näitel".
Andmed on viimati uuendatud novembris 2022. Andmed ja kood on ligipääsetav OSF-is https://doi.org/10.17605/OSF.IO/MDRX7.

Ligipääs ajalehtede täistekstidele toimub nüüdsest OnDemand keskkonnas RStudio kaudu. Keskkonnale ligipääsemiseks kirjutage digilab@rara.ee.
Lisaks dea.digar.ee kasutajaliidesele on teinekord vaja tekstidele otseligipääsu. Selle jaoks on digilabor kasutusele võtnud eraldi keskkonna, kus on võimalik ligi pääseda soovitud tekstide toorandmetele, töötada nendega R-i koodi kaudu ja nii andmeid kui analüüsitulemusi endale arvutisse laadida ja teistega jagada. Tekstide kasutamisel ja taaskasutamisel tuleb jälgida litsentsitingimusi.
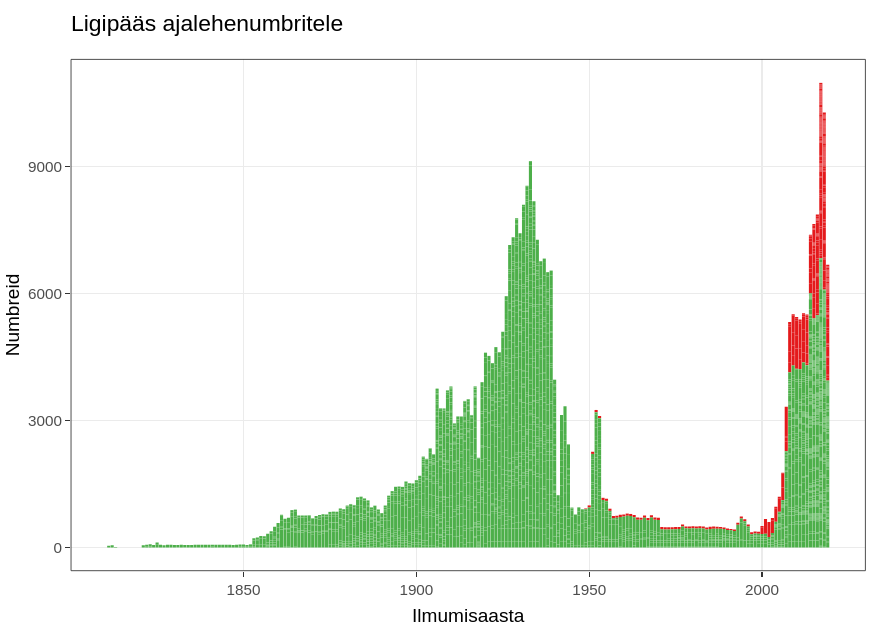
Ligipääs failidele on toetatud R-i paketi poolt digar.txts, mis paari lihtsa käsuga 1) annab ülevaate andmekogust koos seostega failidele, 2) võimaldab moodustada andmestikust vajalikke alamhulki, 3) võimaldab teha tekstiotsingut ja 4) võimaldab otsingu tulemustes võtta välja leidude vahetu konteksti. Otsingu tulemused võib edasi salvestada ka tabelisse ja töötada juba väiksema koguga edasi mujal.
Need käsud on:
Vahepealseks töötluseks sobivad igasugu R-i paketid ja käsud. Töötluseks Pythonis tuleks andmed enne kokku koguda ja teha uus Pythoni märkmik.
suppressPackageStartupMessages(library(tidyverse,lib.loc="/gpfs/space/projects/digar_txt/R/4.3/"))
suppressPackageStartupMessages(library(tidytext,lib.loc="/gpfs/space/projects/digar_txt/R/4.3/"))suppressPackageStartupMessages(library(digar.txts,lib.loc="/gpfs/space/projects/digar_txt/R/4.3/"))all_issues <- get_digar_overview()library(tidyverse)
subset <- all_issues %>%
filter(DocumentType=="NEWSPAPER") %>%
filter(year>1880&year<1940) %>%
filter(keyid=="postimeesew")subset_meta <- get_subset_meta(subset)
#potentially write to file, for easier access if returning to it
#readr::write_tsv(subset_meta,"subset_meta_postimeesew1.tsv")
#subset_meta <- readr::read_tsv("subset_meta_postimeesew1.tsv")do_subset_search(searchterm="lurich", searchfile="lurich1.txt",subset)Vaikimisi otsib pakett läbi artiklite kaupa esitatud allikatest. Mõned allikad ei ole segmenteeritud artikliteks ja on ligipääsetavad ainult lehekülgede kaupa. Lehekülgede kaupa otsimiseks kasuta lisaparameetrit source.
do_subset_search(searchterm="lurich", searchfile="lurich1.txt",subset, source= "pages")Otsida võib ka lemmatiseeritud tekstidest, sel juhul määratle ka searchtype.
do_subset_search(searchterm="lurich", searchfile="lurich1.txt",subset, source= "pages", searchtype="lemmas")texts <- fread("lurich1.txt",header=F)[,.(id=V1,txt=V2)]concs <- get_concordances(searchterm="[Ll]urich",texts=texts,before=30,after=30,txt="txt",id="id")Märkus: et kasutada ctrl+shift+m klahve %>% toru kirjutamiseks Jupyteris, tuleb lisada väike koodijupp. Selleks mine Settings -> Advanced Settings Editor… -> Keyboard Shortcuts vasakul pool User Preferences kastis ja lisa sinna järgnev kood. ctrl+shift+m peaks nüüd töötama.
{
"shortcuts": [
{
"command": "notebook:replace-selection",
"selector": ".jp-Notebook",
"keys": ["Ctrl Shift M"],
"args": {"text": '%>% '}
}
]
}Andmetega töötamisel soovitame lähtuda avatud teaduse põhimõtetest. Selle tööriista kontekstis vaata selleks juhendit siin.
Perioodiliselt uuendatav ülevaade DEA tekstide kollektsioonist on näha siin.
Käsud on koondatud R-i paketti, mis on hoiustatud githubis https://github.com/peeter-t2/digar.txts. Kood töötab keskkonnas pärast sisse logimist. Andmed on hoiustatud ETAIS-i serveris ja ligipääsetavad paketi abil (vt juhend) või käsureal.
Ülevaate tegemise kood ja andmed on OSF-is https://doi.org/10.17605/OSF.IO/3GZXE.
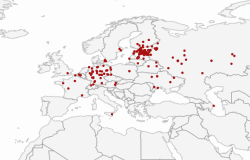
Rakendus on eraldiseisvana leitav veebilehel: https://peetertinits.github.io/reports/nlib/all_works_geo.html
Eesti Rahvusbibliograafia metaandmetes on enamike raamatute juures kirjas ka nende avaldamise koht (see, kus asus kirjastus). Siinses tööriistas on andmestikust ülevaate saamiseks loodud seos kohanimede ja koordinaatide vahel ja paigutatud raamatud ilmumiskoha järgi kaardile.
Kaardil on näidatud iga kümnendi kohta, kus raamatuid ilmus ja kui palju. Kaardil on võimalik muuta ajahetke mida kuvatakse, vaadet suurendada ja fokuseerida teatud kohale ja veidi lisainfot saada koha kohta, mis on kuvatud. Mida suurem ring, seda rohkem teoseid ilmus neil aastail selles kohas.
Punktidel on võimalik klikkida, et saada selle ajastu Esteri kirjed. Esteris on rohkem kirjeid kui Eesti Rahvusbibliograafias, kuna ta sisaldab ka mitte sel viisil Eestiga seotud teoseid.
Märkus: Geograafiliste asukohtade märkimisel on mõningaid vigu, need on seal peamiselt seetõttu et maailmas on hulk sama nimega kohti. Need vead on parandamisel.
Andmed on viimati uuendatud juunis 2023. Andmed ja kood on ligipääsetav OSF-is https://doi.org/10.17605/OSF.IO/WE7KT.

OAI-PMH protokoll on Open Archives Initiative loodud standard, mis pakub infosüsteemist sõltumatut koostalitusvõimelist standardit metaandmete jagamiseks ning kogumiseks. Metainfo, mida üle OAI-PMH protokolli saadetakse, on XML vormingus.
OAI-PMH standard kirjeldab järgnevaid päringuid ja meetodeid:
Rahvusraamatukogu OAI-PMH serverile saadetavaid päringuid on võimalik täiendada/piiritleda ajaliselt, vorminguliselt kui ka erinevate kogumite kaupa kasutades järgnevaid parameetreid:
Tulenevalt OAI-PMH standardist on olemas kaks võimalikku viisi, kuidas ehitada liidese töötamise loogikat – kasutada ListRecords päringut või ListIdentifiers ja GetRecord päringut koos.
Kui kõik allikad ja allika kohta käivad metaandmed ei ole olulised ja huvitab ainult tekstiline sisu ning OAI-PMH protokolli kasutada tundub liigselt keeruline võib päringuid saata ka otse dea.digar.ee süsteemi kasutades jõu meetodit. Võttes aluseks Eesti Rahvusraamatukogus registreeritud ajalehtede nimistut ja igale lehele omistatud koodi on võimalik pärida dea.digar.ee baasist järgmise süntaksi abil. http://dea.digar.ee/article-text-XML/[ajalehekood]/[aasta]/[kuu]/[päev]/[artiklinumber].1
artiklinumbrit suurendada seni kuni süsteem tagastab XML vastuses tagi.
Dublin Core Metadata Element Set, Version 1.1 (14.07.2017) vt. http://dublincore.org/documents/dces/.
DCMI Metadata Terms (14.07.2017) vt. http://dublincore.org/documents/dcmi-terms/.
MARC to Dublin Core Crosswalk (14.07.2017) vt. https://www.loc.gov/marc/marc2dc.html.
Dublin Core to MARC Crosswalk (14.07.2017) vt. https://www.loc.gov/marc/dccross.html.
MARC21 ja Dublin Core lihtsustatud väljade kirjeldused:

Eesti Rahvusraamatukogu andmebaase DIGAR ja DEA tutvustav video:
Eesti rahvusbibliograafiat tutvustav video:
Eesti Rahvusraamatukogu
Tõnismägi 2, 10122 Tallinn
+372 630 7100
info@rara.ee
rara.ee