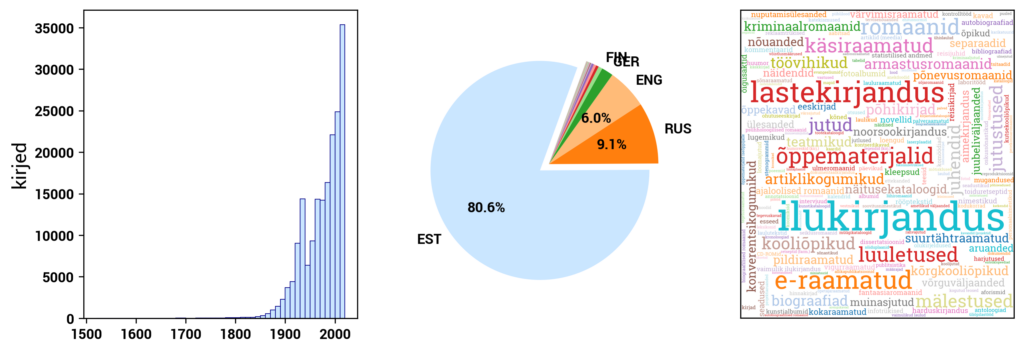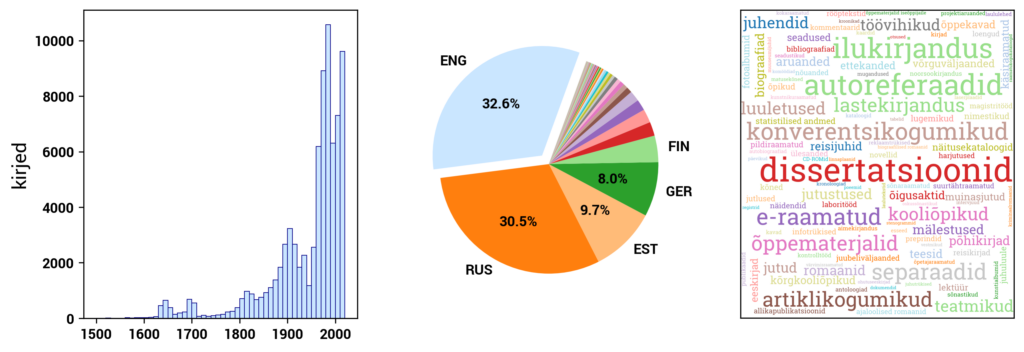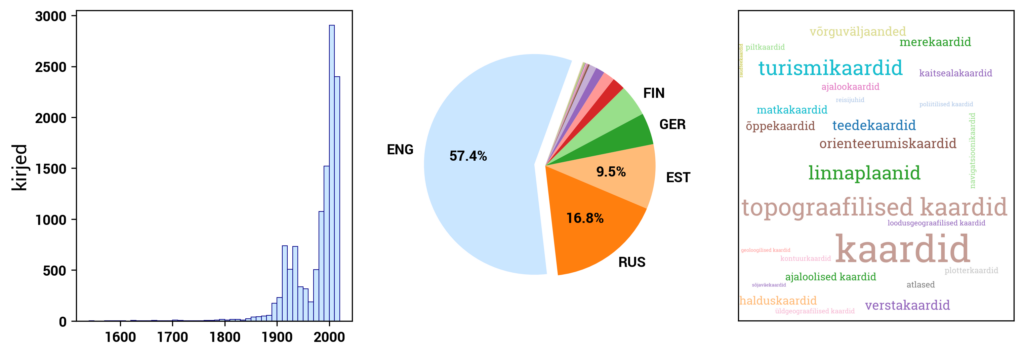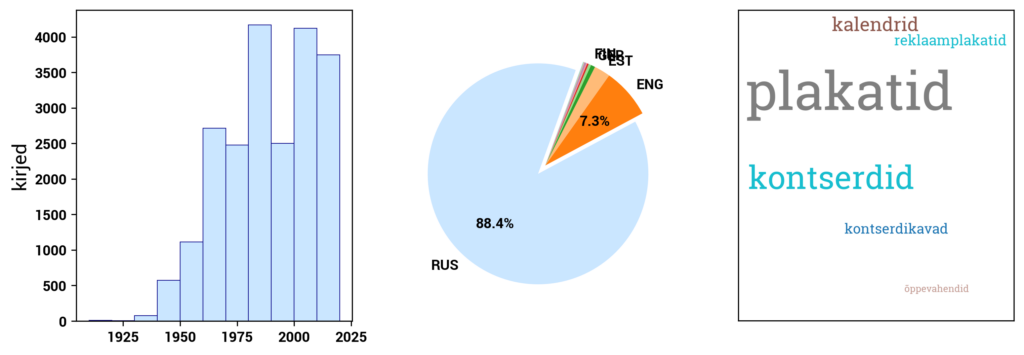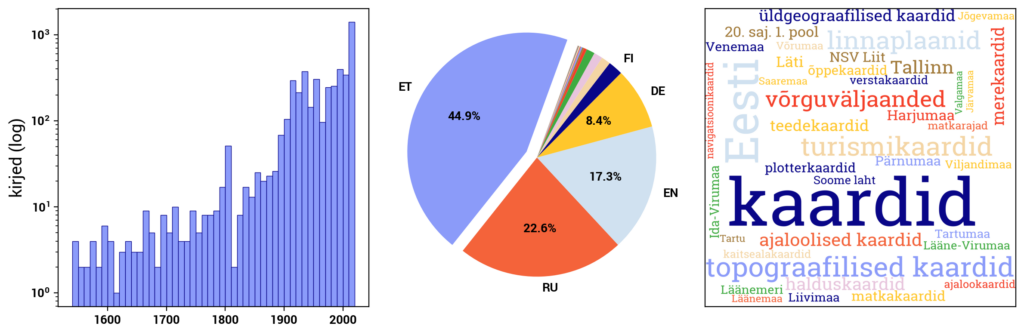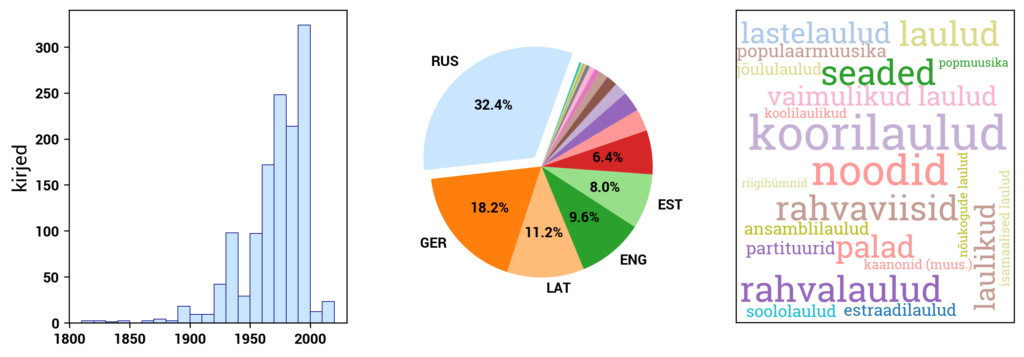
Currently, Digilab primarily includes datasets created based on the digital collections of the National Library of Estonia. In addition, Digilab also includes data from the Estonian Thesaurus, and in the future, other cultural heritage datasets will be added as well.
RaRa datasets consist of three main components: the digital archive DIGAR, the digitized Estonian Articles DEA, and the Estonian National Bibliography ENB. DIGAR contains various types of data, such as books, periodicals, maps, sheet music, and postcards. These can be accessed separately in Digilab. DEA primarily includes newspaper texts but also includes more recent periodicals. ENB contains metadata about print publications published in or related to Estonia. The datasets in Digilab are created to provide direct access to the underlying data behind the user interface of the digital collections. The datasets and associated information are continually updated.
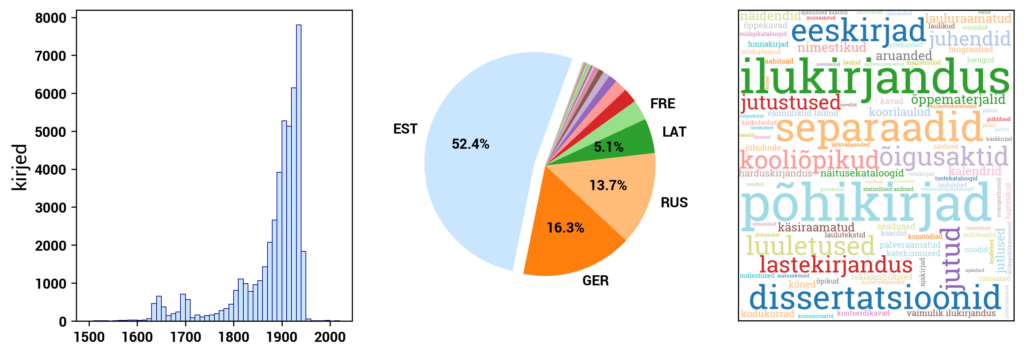
Estonian National Bibliography
The Estonian National Bibliography database ERB (www.ester.ee/search~S95*eng) registers data about national publications. National publications include all publications published in Estonia in all languages and publications published in Estonian abroad, including works by Estonian authors and their translations, regardless of their physical format (paper, electronic). The principles for compiling ERB are defined in the document "Principles of National Bibliography Compilation." The database is continuously updated with new data, at least once a week.
During the registration process, a detailed description is created for each publication based on the information contained in the publication. The description includes the title, information about the responsible individuals and organizations for the publication, publisher and printing house details, edition information, physical description (pages, dimensions, etc.), and affiliation to any series. In addition, search features such as keywords, subject indexes, and standardized forms of names for related individuals and organizations are added to the description.
All data in the database adhere to international standards:
- ISBD (International Standard Bibliographic Description) – for descriptive data;
- AACR2 (Anglo-American Cataloguing Rules 2) – for search features;
- UDC (Universal Decimal Classification) – for subject indexes;
- MARC21 – used as the data exchange format.
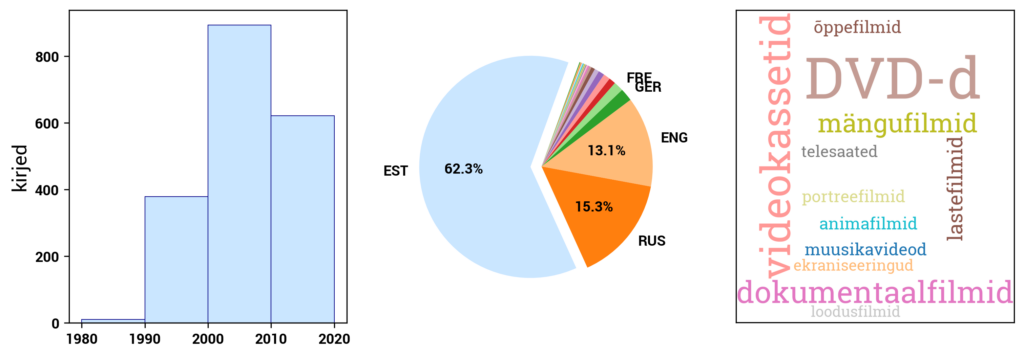
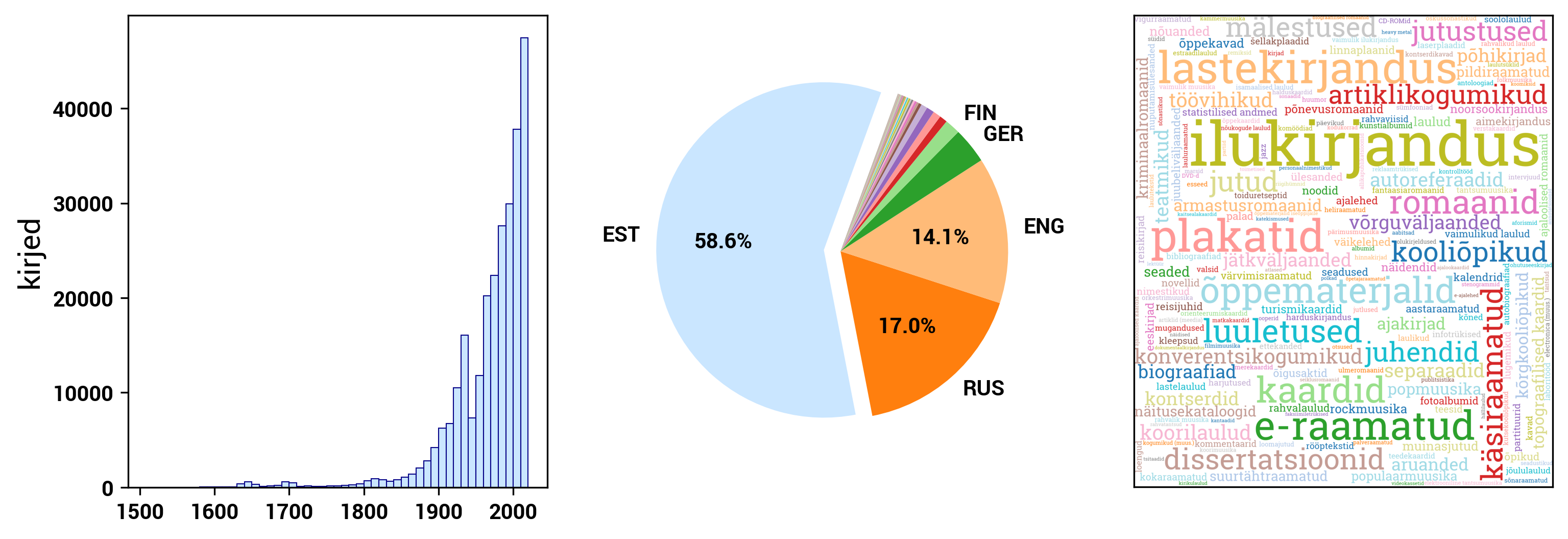
The open data in ENB is categorized into groups based on material types: books, periodicals (journals, newspapers, continuing resources), maps, scores, video recordings, audio recordings, image materials, and multimedia resources. In the case of books, the data is further divided into Estonian books and non-Estonian books.
The data of individuals and collectives in the Estonian National Bibliography is also separately available.
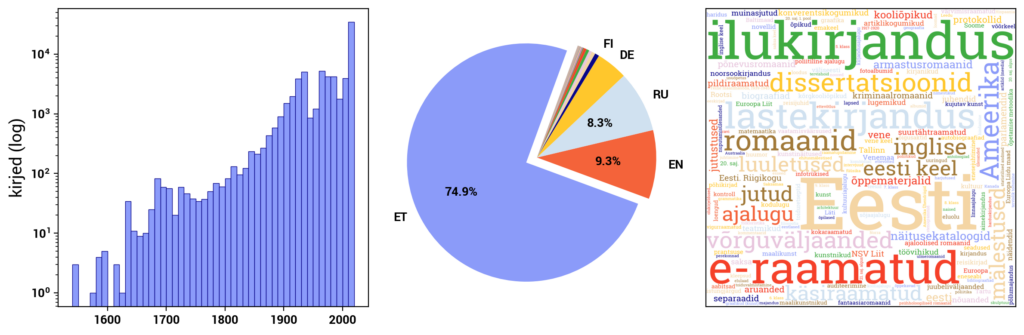
The National Library of Estonia's digital archive DIGAR
DIGAR (www.digar.ee/arhiiv/en) is the digital archive of the National Library of Estonia, providing access to publications stored in the digital archive. It includes e-books, newspapers, magazines, maps, sheet music, photos, postcards, posters, illustrations, audiobooks, and music files. The format of books and periodicals is mostly PDF or EPUB, while image materials are in JPEG format, and audio recordings are in WAV format.
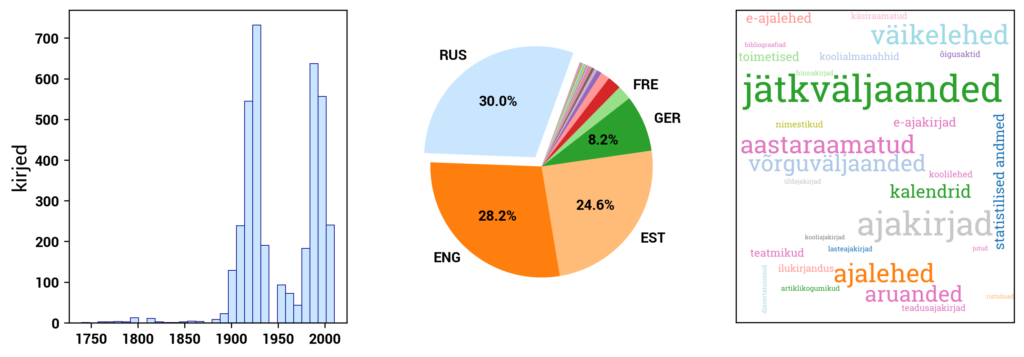
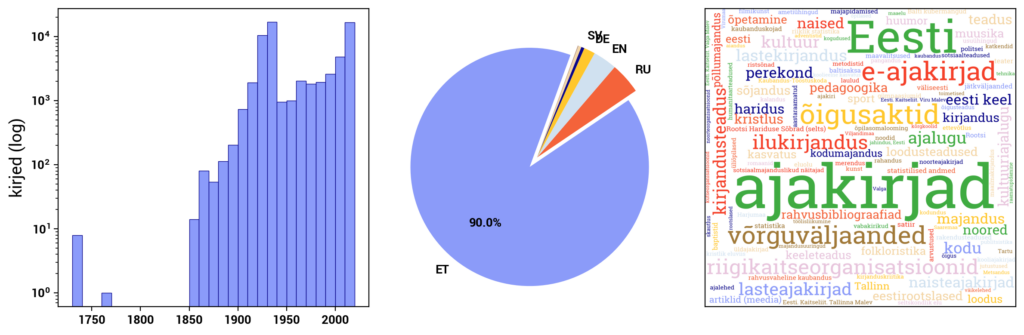
Digitized Estonian Articles DEA
DIGAR Estonian Articles (dea.digar.ee/?l=en) provides access to digitally born and digitized newspapers published in Estonia throughout history, as well as Estonian-language publications from abroad. It includes newspapers, journals, and ongoing publications registered in the annual publication "Estonian National Bibliography. Periodicals" since 2017.
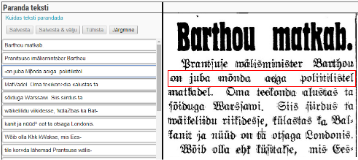
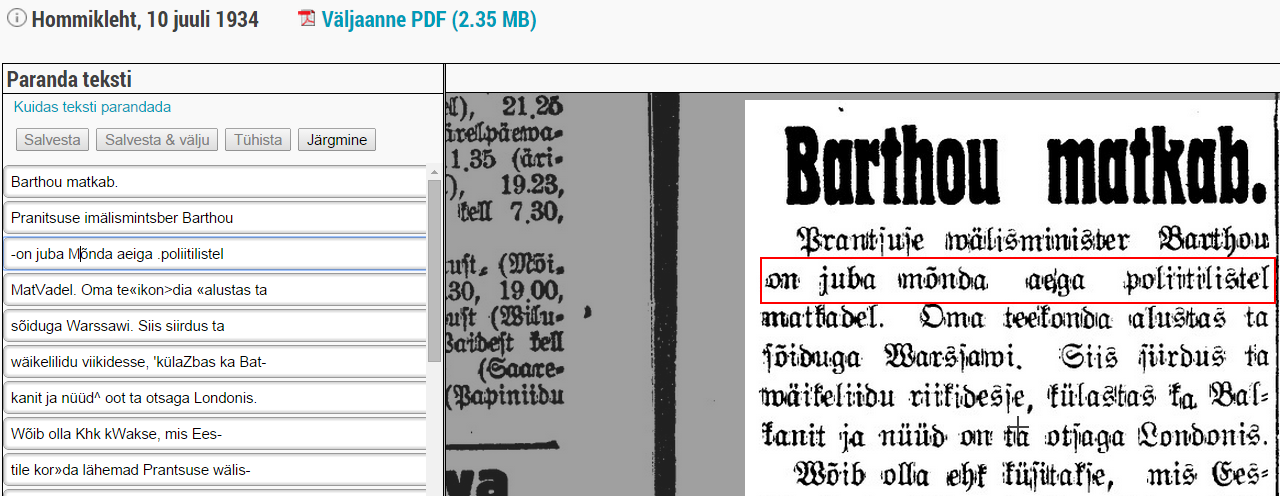
The portal allows users to browse publications, search for content within newspapers, read full-text articles, add keywords to articles, create lists of found articles, and send them via email. Users can also share discovered information on social networks and perform other actions.
Access is provided to newspapers published since 2014, journals and ongoing publications since 2017, and partially to older newspapers. The portal is updated daily. Older newspapers (1821-2013) are gradually added according to a conversion plan.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.