Over the years, nearly 500 users have contributed to correcting the texts in DIGAR, and as a result of their efforts, more than 800,000 lines have been corrected. This dataset contains a selection of pairs of original texts and their corrections.
The dataset, along with its documentation, can be found here: https://zenodo.org/records/13325713
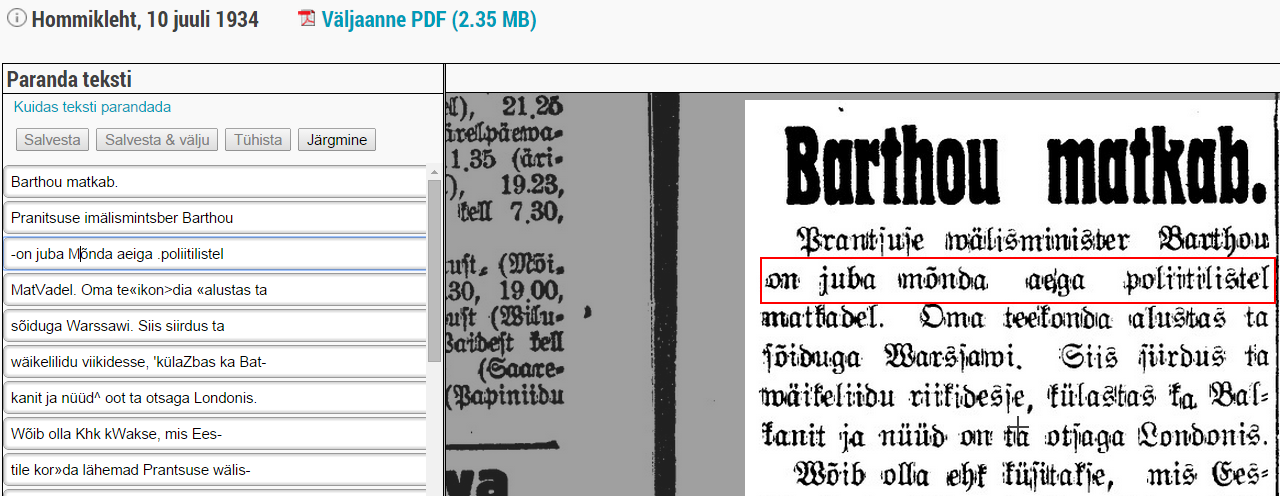
The text corrections in the DIGAR archive are saved as change logs, meaning the original text has been reverse-engineered, with the corrected parts replaced by the original content. The texts are heavily filtered. Specifically, only text correction pairs that meet the following criteria are included:
These criteria are used to exclude texts that are partially edited, contain too many numbers, lists, or other non-alphabetical symbols, or where significant parts have been deleted or added (often to correct segmentation errors).
Since the corrections are the result of collaborative creation, they may contain errors and should not be considered the final truth. To provide a rough overview of the quality of the corrected texts, both the original and corrected texts have been processed through GPT-4o mini, which assigned them a readability score ranging from 1 to 5. The following scale was used for this assessment:
The following is the OCR output from a digitized historical Estonian newspaper from {year}. Analyze the text placed after "TEXT" and decide if it is reasonably free of OCR errors. Return a rating on the scale of 1 to 5.
5 - The text is clear and readable. It may contain unusual spellings and use of punctuation throughout, but there are no distorted words.
4 - The text is readable, but contains some distortions of alphabetical characters. These distortions do not impede understanding the text at any given point.
3 - The text is readable with minor difficulties. Words and phrases may be noticeably distorted.
2 - The text is only readable with great difficulties. All or almost all sentences contain severe errors that make it very hard to understand.
1 - The text is unreadable. It contains mostly gibberish and random symbols, almost no words are recognizable.
If you are hesitating between 4 and 5, it is probably a 5. If you are hesitating between 2 and 3, it is probably a 2.
Note: the use of "w" instead of "v" and "=" instead of "-" are elements of historical orthography an do not count as errors.
Do not reply anything else than a number from 1 to 5, unless explicitly asked to do so.
TEXT:
{ocr_transcription}National Library of Estonia
Tõnismägi 2, 10122 Tallinn
+372 630 7100
info@rara.ee
rara.ee/en