Summary
This blog post explores languages inside the “Russian” part of DIGAR Collection. The metadata for newspapers issued before 1918 shows large number of Russian-language newspapers, however both the page and section-level data provide an evidence that the newspapers were not monolingual and some part of the collection labeled as Russian is in fact in German, Estonian and Latvian. The analysis provided aims to show how the history of Russification in Estonia is reflected in digitized newspaper pages and how metadata issues may probably influence OCR quality.
According to the metadata, a large part of the newspapers issued during the imperial period (before 1917) is marked as Russian-language ones. If counted in pages, there should be more than 120 thousands pages labeled as pages in “Russian” (Language column), with the following total distribution of pages over time:
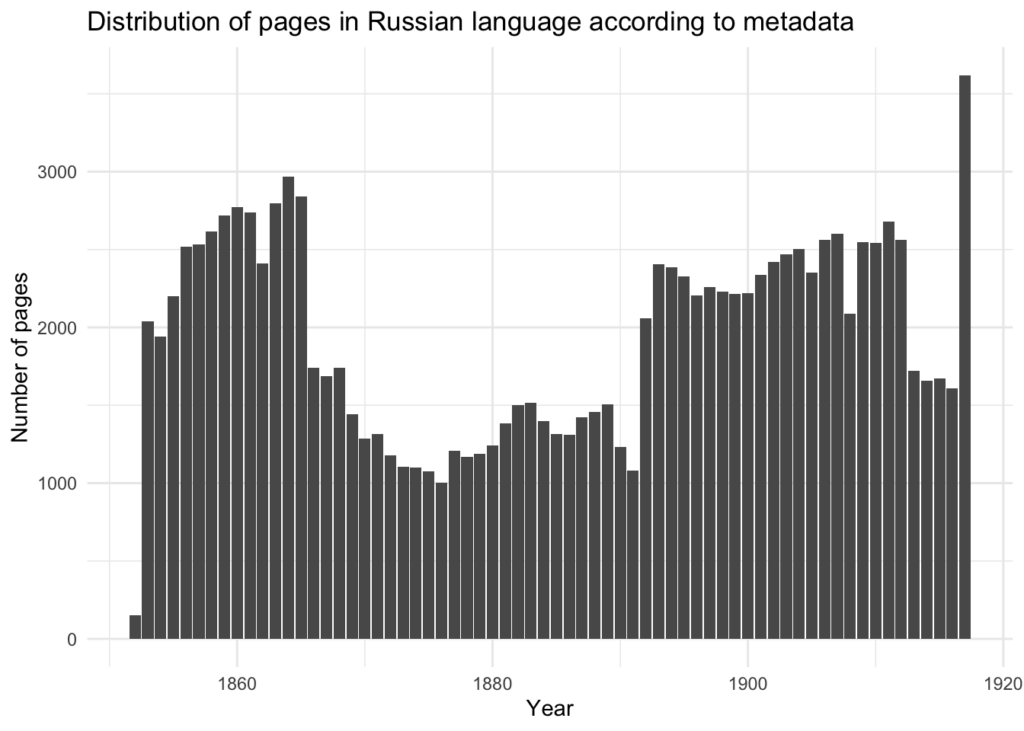
After retrieving these pages’ texts, it is obvious that at least partly the title-level language metadata is wrong: e.g. the earliest “Russian” pages in the collection dated 1852 are mostly in German.
text
1842 sich außer der Stadtbefehlshaberschaft auch auf die Stadt Rostow (im Jekaterinoslawschen Gouvernement) erstreck. Der Procureur d’er StadtbefeHlstzaberAchOßk. d) I n Taganrog. Im Ressort des Ministeriums des Innern: Die Taganrogsche Stadtpolizei, unter der Das Polizeiwesen nicht nur in der Stade Taganrog, sondern oud) m dem dazu gehörenden Kreise steht. Die Taganrogsche Stadt-Duma. Die Taganr
0тд елъ второй. Zweite Abtheilung. Часть оффициальная. Officieller Theil. Durch Allerhöchsten Tagesbefehl im CimlRessort vom 19» October 1852, Nr. 269, sind bestätigt: Als Rigascher Ordnungsrichter Major von Tiesenhausen, der auch schon bei frühem Wahlen dieses Amt bekleidete, und als Dörptscher der im Jahre 1836 aus der 11» ArtillerieBrigade als Stabs-Capitam entlassene von Oeningen. Als Adju
Md. XIV. Ust. über Pässe und Läuflinqe Art. 589. Nr. 82. ’ Diebstahl. Publication der Strafbestimmungen für denselben. Nr. 85 u. 86, lettisch und ehstnisch Nr. 91 u. 92. Dienstboten-Bücher Nr. 54, lettisch und ehstnisch Nr. 55, deutsch, lett. und ehst. Nr. 56. Ausreichung derselben Nr. 61. Verbot aller Rügen und Bemerkungen über die Führung Nr. 78, 79, 81. Don au-Fürstentümer, vide Manifest. Dorpa
Language detection
To make a new rough language detection an R-package textcat was used. It takes a text as a string and calculates its average score to detect a language, so as a result a new metadata column will have one most probable language detected for each page.
A better solution may be found here, since many pages will probably have several languages combined at one page. However, this package is still applicable for a rough estimation of major languages proportion in these pages.
textcat language detection is not ideal, the full set of detected languages shows how low-quality OCR influences the results. Few pages were tagged with languages very unlikely used in Estonian newspapers, such as Nepali or Indonesian. The language distribution for the languages appearing in at least 150 pages is the following:
##
## estonian german latvian russian ukrainian
## 699 49328 128 74815 3102However, even the “Ukrainian” pages should be excluded from the analysis, since these pages are in fact badly OCR-ed pages in Cyrillic script. Randomly selected chunks shows these pages are mostly in Russian, but being unable to check them all I filtered these pages as highly messy and unpredictable. This result is very disappointing showing not a language diversity but issues inside tools trained on major languages and giving an imperialistic assumption on Ukrainian being (on the character level) a messy Cyrillic which is not Russian (see an example below).
text
4 Р е в е л ь о x I н fl I :i lotis. M 259 О К Ъ Я В Л К П I я. отъ эстляндской КАЗЕННОЙ ПАЛАТЫ ОБЪЯВЛЕНИЕ. Уъзлнын Казначейства Везенбергское. Вейсенштейнское и Гапсальское, Эстляндской губернш, будутъ производить съ 1-го января 1897 г. слЬдующш байковый oiiepuuiii: 1) размъпъ денегь крупныхъ кредитных!, билетовъ на мелка*, мелкихь на крупные и ветхнхъ на годные къ обращешю; 2) покупку бнлетовъ
Ui urm paifUiitMB, t. Рмш, 87-y, urym 1900 ff. Пив11я1Йи|ц ■—ууп. ТамграфЫ (umt;.r«aib«aia Uua.-«iB’. 4 Р в в е ль oxl а И tat о! а. «19: ОБЪЯВЛЕН! Я. Упраие ul’ BajTlBcKol и Вомм-Тижгко! жмЪшъиъ дорогъ >тр» Вслв »» n npun торги» nnrimiiM « »yxert ар.ххож-«о «kau porno »kau. TO. »a oceoaaaia jj 11 oaaaomuik MpaaaJV будет» арогааеде» ifrjiufuol «tau ТО», pork - 14 Дгаавра IMI r. i баг
Рмми F tr« И »»HlUi Б Ъ М R .1 В В I Г М 246. •а j О .•га ИЯИИНДЙЙИКЯКЙКиц ДДЙЙЙЙЙЙ Д и м£Д Я KjlH И Н Д Д Н Н Н Н И И Н Ц U К|Д Ц|Ц ИДИ Н.ЙДЙ ДЙ ДЙЙЙЙ я ОТКРЫТА ПОДПИСКА ЗЩГ на 1894 годъ ““W>’ на егедиеввую газету мЪстныхъ интересовъ, литературную и политическую „РевеjbCKifl lüitem“ Подл. цна: съ Перес, и дост. на 1 годъ … & руб. — коп. » » » т 6 м*сяцевъ . Q » — » » » » на 3 » .
If we exclude the “Ukrainian” from consideration, this is the language distribution obtained with textcat language detection:
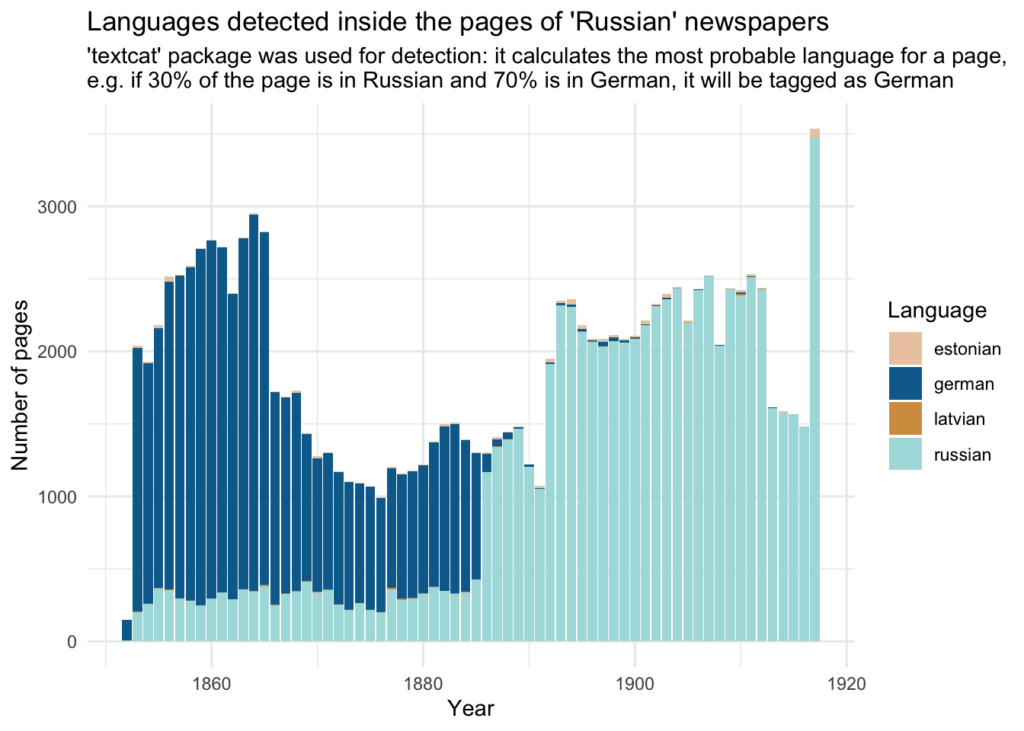
I believe this result is important, since it clearly shows that part of the metadata labels for “Russian” language used in 19-century newspapers should be reassessed: clearly, these are newspapers in German.
At the same time, I find this language switch from German to Russian in late 1880s very convincing, since the 1880s are known as a Russification period. Curiously enough, it happened very abruptly, so it might be interesting for further researchers to see if the content of newspapers switched from German to Russian changed significantly.
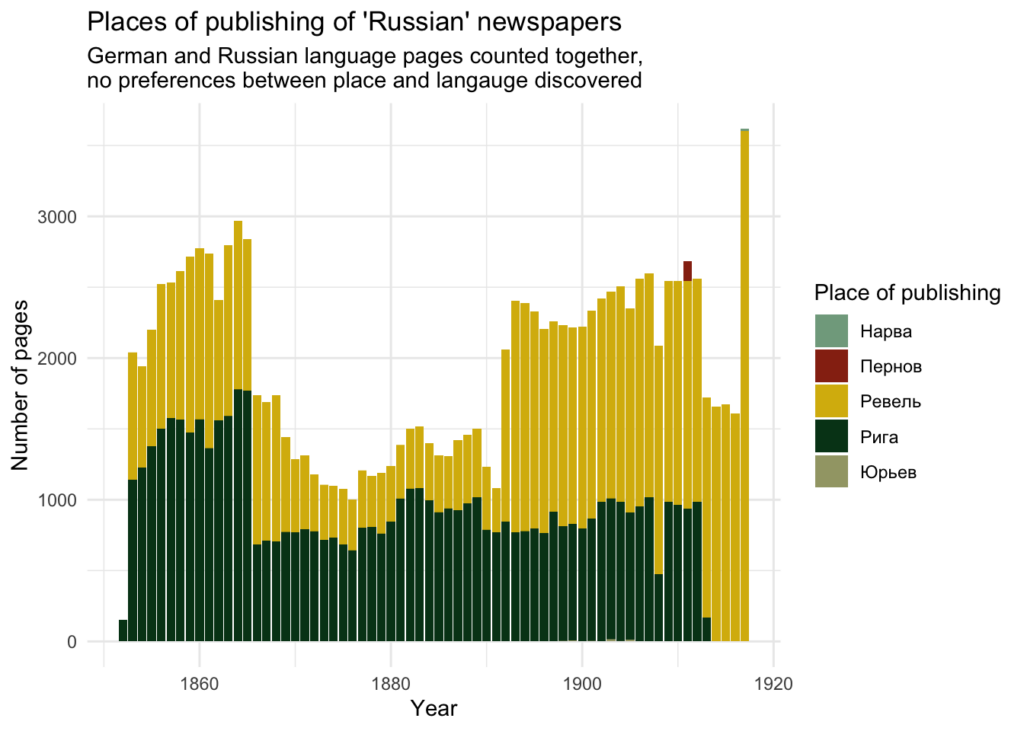
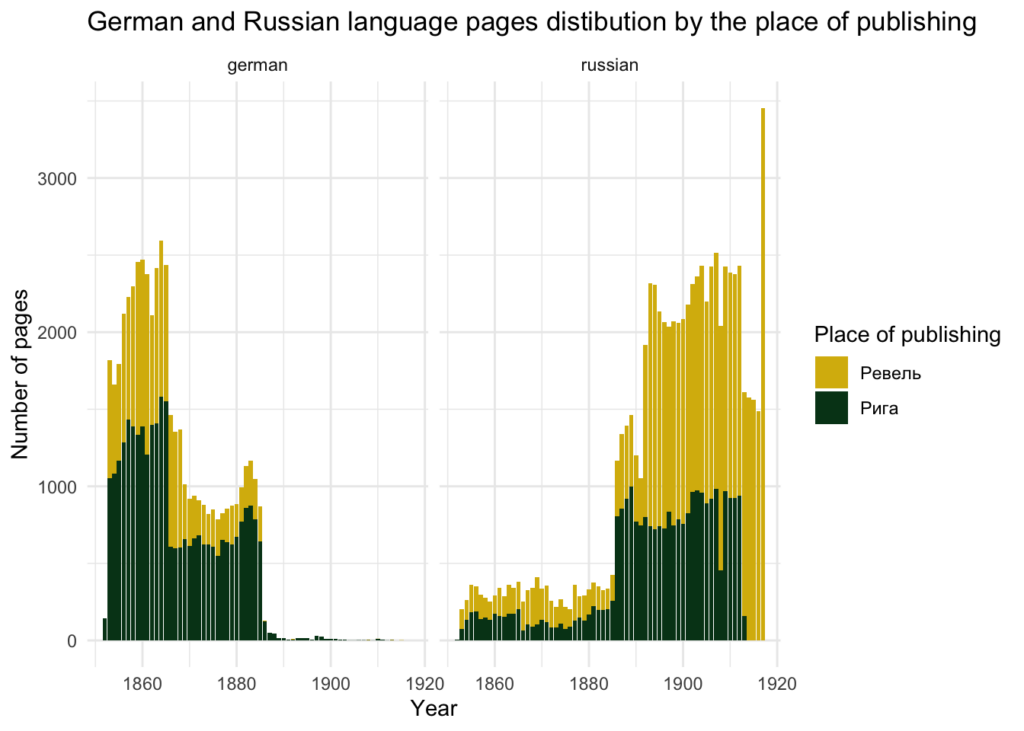
To add more details, the language distribution does not depend on place of publishing, which in overwhelming majority of cases are Riga or Tallinn (Revel):
OCR accuracy & languages
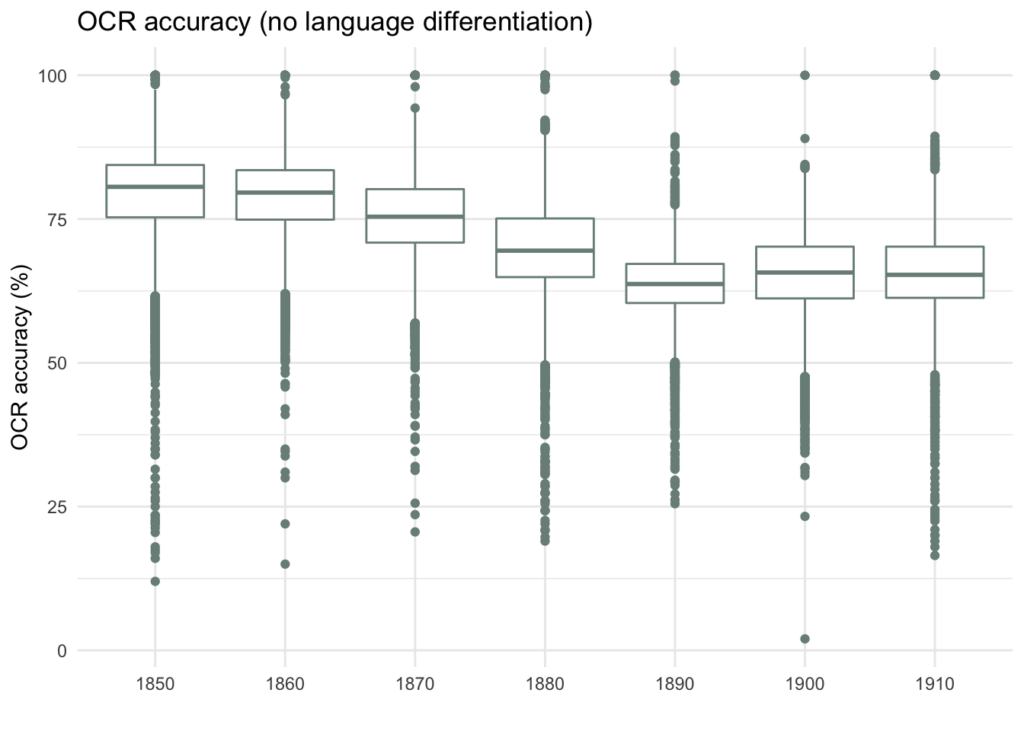
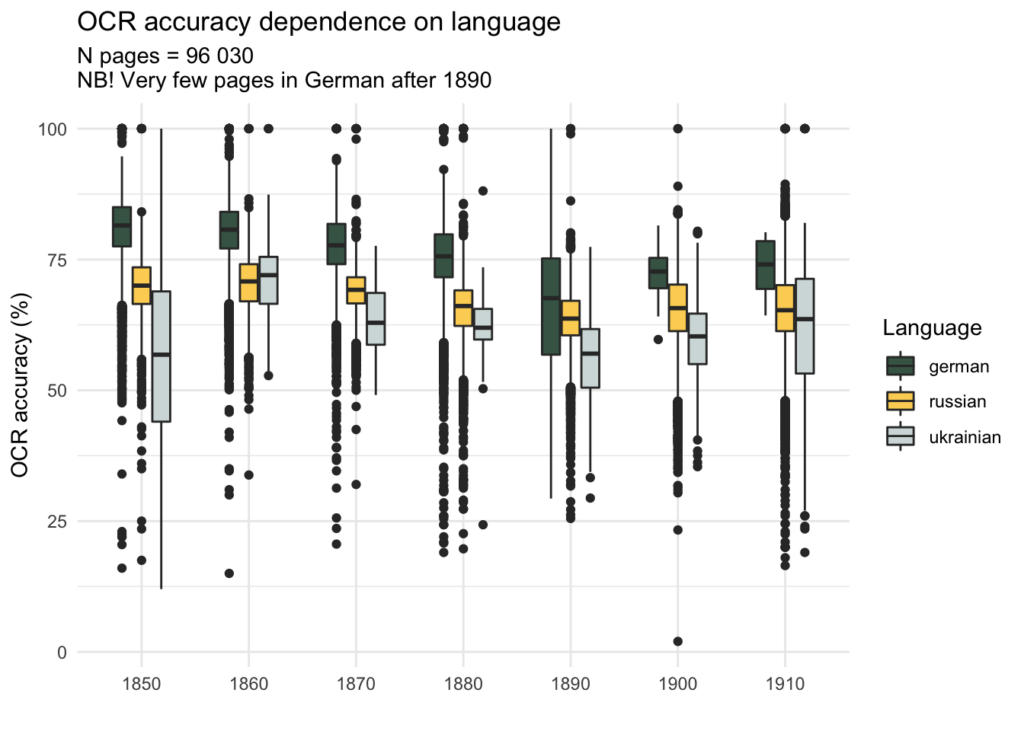
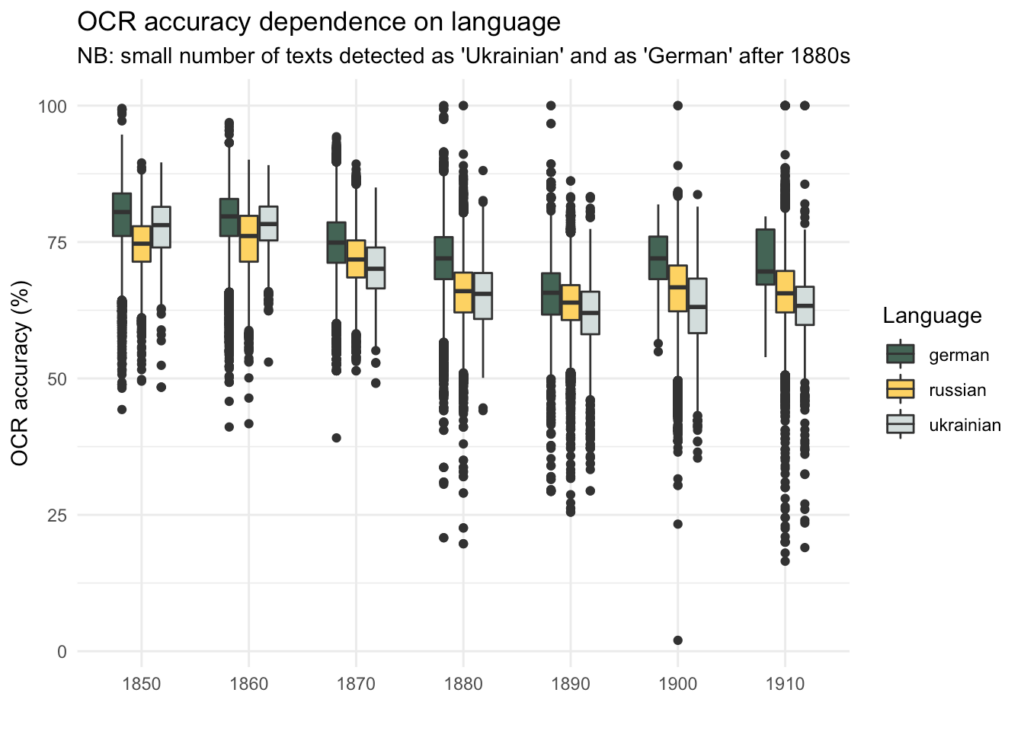
From a technical point of view, the languages (or scripts) hidden behind the “Russian” tag in metadata seems to be important for the OCR quality. If we are to plot OCR accuracy values for decades it may seem that there is a decrease in 1880-s, as one might suppose, led by Russification. This is, however, misleading, because the reason behind the decrease is different OCR accuracy for German and Russian (or Latin and Cyrillic scripts in general). The plot below displays how the OCR quality distributed according to the new language metadata; it is also visible that pages detected as “Ukrainian” have very low OCR quality.
To sum up, language reassessment on a more granular level (i.e. section) seems important and feasible to be added to respective metadata entries and then grouped to multilingual labels for the language data of entire newspaper titles.
Report update: 10/11/2022
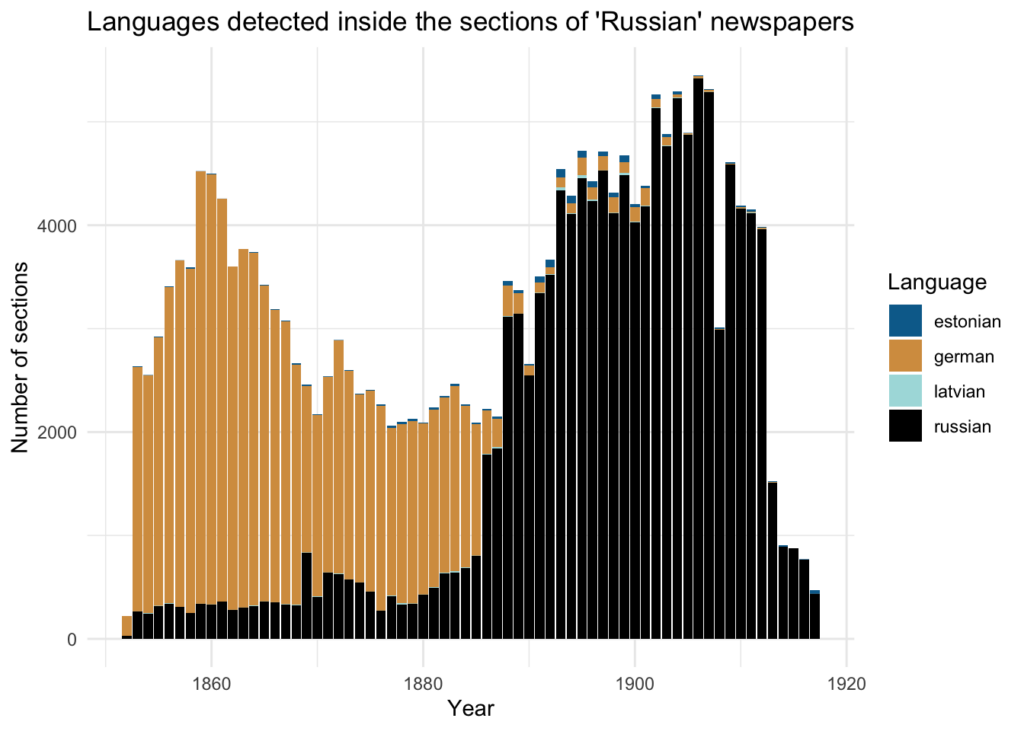
The part above showed the difference between title-level language metadata and actual languages used in the governmental newspapers in the collection: while the newspapers’ language defined as “Russian”, digitized materials allow to conclude that newspapers used predominantly German as a language of communication until mid-1880s. The analysis was done on the page level, determining the proportion of languages used and labeling each page with most probable language. The results might be yet improved using as input data not the whole pages but newspaper segments or sections, where each section will most probably be written in only one language.
This update of the report aims to demonstrate results from the language detection made on the section level. However, as sections division is available at the moment only for the two newspapers, the results below cannot be directly compared to the analysis done on the full corpus (namely, the sections are available only for Estonian and Livonian governorate official newspapers, shortened in the dataset as ekmteataja and livzeitung respectively).
The languages of sections were detected with the textcat package as in the page-level analysis.
Ten most common languages for sections are mostly the same as the ones detected on the page level; the probability of error is higher for small sections (in particular, the ones that include less than 20 words).
| language | n_sections | percentage |
|---|---|---|
| russian | 126937 | 56.84 |
| german | 83578 | 37.42 |
| ukrainian | 6257 | 2.80 |
| english | 1495 | 0.67 |
| estonian | 1299 | 0.58 |
| bulgarian | 1078 | 0.48 |
| middle_frisian | 886 | 0.40 |
| rumantsch | 305 | 0.14 |
| latvian | 290 | 0.13 |
| belarus | 276 | 0.12 |
Such unexpected (for Baltic newspapers) languages as English, Bulgarian and Rumantsch appeared to be detection errors for short sections with low OCR quality. Unfortunately, as well as in the case of page input, Ukrainian and Belarus languages are detection errors most probably caused by poor OCR and/or lack of training data for detecting these languages. The examples taken randomly for each of the false-detected language are shown below.
| lang | text |
|---|---|
| belarus-windows1251 | ZiüMv-ZlonnW Нар. изд. Я. Верм ана. Для ознакомлешя одна км. высыя. беаалатнв. Сяб.. Фонтанна ?j. |
| bulgarian-iso8859_5 | Став Отправлешя. ц i в: Нааначен1я. накладных^ Время отправления. Отправитель. Получатель. Родъ товара. ВЪсъ. II. Ф. Цвинскъ Модонъ 5043 15 сентября Хаймъ ВалПредъявит. Веревки . . . 5 05 1903 г. лерн!тейнъ дубликата Шпагать пеньковый …. 2 20 Рига тов. Модонъ 92243 13 сентября Отокаръ Предъявит. Кондяторемя то1903 г. Войта дубликата варъ …. 8 01 Рига тов. Модокъ 92617 13 сентября Шааръ иКаПредъявит. Впно виноградное 7 — 1903 г. внцель дубликата Правлен1е . |
| english | ЧАСТЬ ОФФИЦИАЛЬНАЯ. Отделъ местный. Officieller Theil. Locale Abtheilung. |
| ukrainian-koi8_r | П ММЦШ ГЛВЯОП* ТШЮГРАФМ ( Зяьмоигх») посту лиди въ продажу отдЪаышми брошюрами; ОБЯЗАТЕЛЬНЫЙ ПОСТАНОВЛЕНЫ Рижской Городской Дупы. X. О распорядк! на Рижскихъ рынкахг. XX. Для заведений трактирнаго промысла въ город! Риг!. тгг. О содержали пиеныхг, портерныхъ и питейныхъ лавонъ, а равно ренсковыхъ погребовъ съ распивочною продажею кр!пнихг иапитковг. lüim OO коп. |
Nevertheless, textcat package output seems to be true for the sections labeled as Latvian or Estonian even for cases when several languages are mixed inside a section, e.g.:
| lang | text |
|---|---|
| estonian | Kulutus. Liiwlandi Kubbernemango Wattitsus on Patenti läbbi sest 16. Oktobrist 1862, Nr. 71 ja Liiwlandi Kubbernemango Tseitungi läbbi sest 11. Aprilist 1855, Nr. 42 teada aimud, et ükspäinis Priwati- rahwas sedda makso Liiwlandi Kubbernemango Tseitungi eest Posti Kontori jures woiwad sissemaksta; agga et keik kohtud ning seadusse ammetid, kes tahtwad Kubbernemango Tseitungid piddcida, muudkui mitte mõisa- egga watta-wallitsussed ja kihhelkonnakohtud peawad maksorahhad taieste Kubbernemango Wallitsusse kätte saatma, ja et ja watta-wallitsussed ning kihhelkonna - kohtud peawad sedda makso omma kohhalisse Sittakohto jures sissemaksma. Et nüüd kül se käsk sai antud, siiski on mitmel korral Liiwlandi Kubbernemango Wallitsussele teada antud, et paljo mõisad, selle assemel, et nad peaksid omma makso Sillakohta jures sissemaksma, saggedaste agga iittestumnstanud, et nemmad tahtwad sedda makso Liivlandi Kubbernemango Tseitungi wäljaandja jures stssemaksta: agga kui järrele nõutakse, kas on ka |
| latvian | !!Walmeerâ!! Preeksch wifadeem godeem peedahwa grun, tiguwihnu, konjaku. araku, ruviu. likeeruS un wisadus fchehlHinuS no teem wisslaweliateem wihna pagrabcem un spirtus destilaturahm par mehreenu zenu pee laipnigaS un labas apdeenefchanas. Pee pllnigahm eepirkfchanahm ari apfofu traukus bes kahdas atlihdsinafchanaS aisdot. R. W. Müller, materialu- un perwju bode, wihna- ua fpirtus kantoris. Bijuschä meesneeka Zack k. namä Rr. 90. P. Schilling’« un jitäs grahm. bodes dabujama fchahda eewehrojama grahmata: Kreew« - Tnrku kara-krouika 1877 un 1878. Pehz kcna-prateju un wehsturigahm fi«ahm fastahdijis LapaS Mahrti«fch. Schis pilnigais pehdeja kara apraW tfnahks 10 lihds 12 burt» ntzkS ar flawenu generalu un diplomatu bildehm (katra burtnize ir dtwi bildes). 8 burtnizeS Ir jau zita» ifnahkS drihfä laikä. Kurfch wisaS burtnizeS buhs pirziS, dabuhs par prehmiju teetu j auku bildi „Kautinfch pee Schipkas grawaS”” partikai 25 kap. (Tchi bilde roifu raafaff 1 rbl. 25 kap.) Tas no wiseem labp |
Selecting only Russian, German, Estonian and Latvian sections, the distribution of languages in sections is the following:
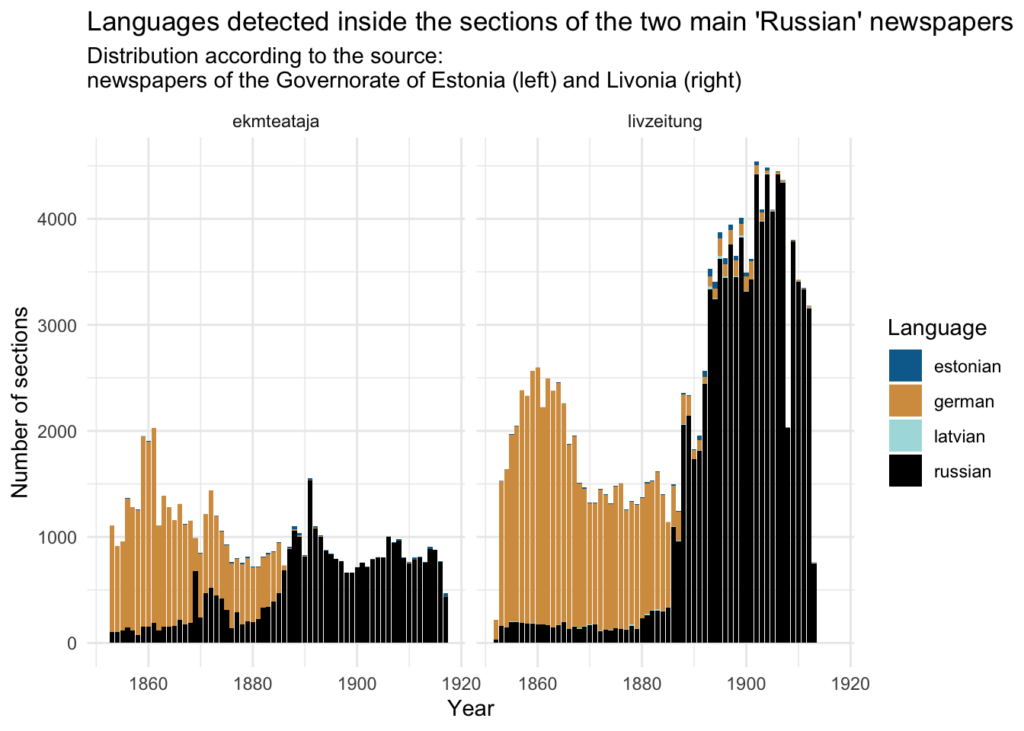
Number of sections and words in each language:
| Language | Newspapter | N sections | N words |
|---|---|---|---|
| estonian | ekmteataja | 405 | 143706 |
| estonian | livzeitung | 894 | 780308 |
| german | ekmteataja | 28797 | 12644769 |
| german | livzeitung | 54781 | 30316848 |
| latvian | livzeitung | 290 | 180542 |
| russian | ekmteataja | 35204 | 23334143 |
| russian | livzeitung | 91733 | 36699193 |
As sections differ in length, there is a possibility that counting sections (previous plot) might not reflect the actual proportion of languages used in texts of different languages. This assumption can be tested using number of words in each section (LogicalSectionTextWordCount in the metadata). The main assumption is that one section was in most cases written in one language (thus the same method seems less applicable to pages). Resulting distribution is very similar to the section count showed above:
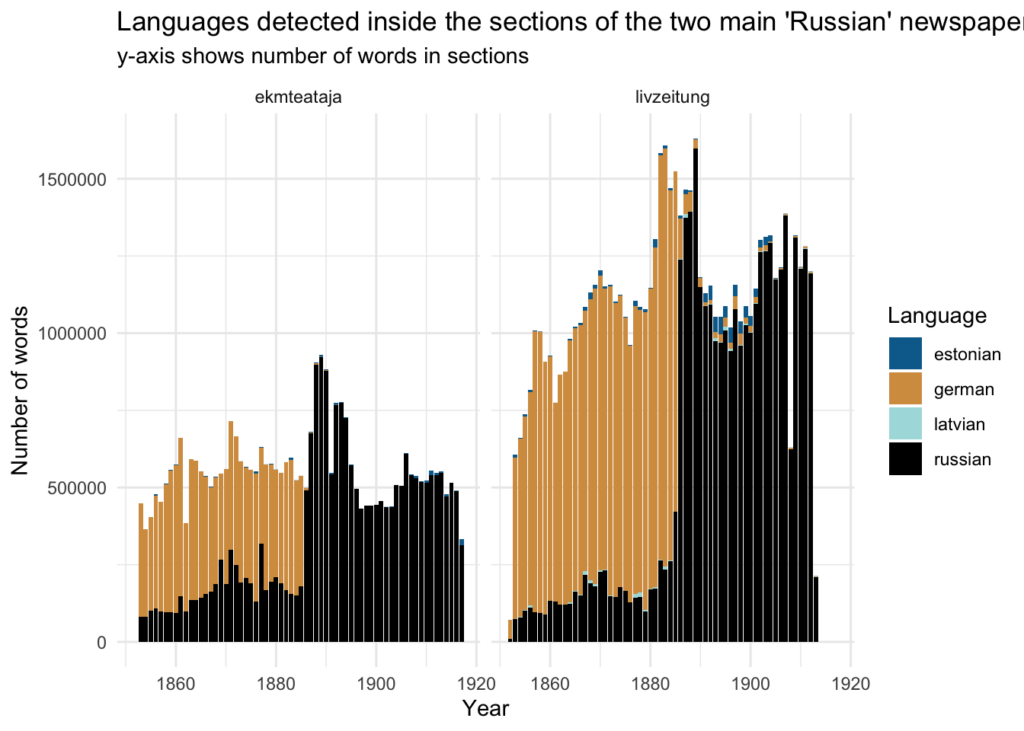
To compare the results with the page-level language detection, it is possible to filter only ekmteataja and livzeitung from the results gathered previously (stored in data/01_pages_meta_rus_lang.csv). The main shift from German to Russian and the proportion overall seem roughly same as in the case of sections.
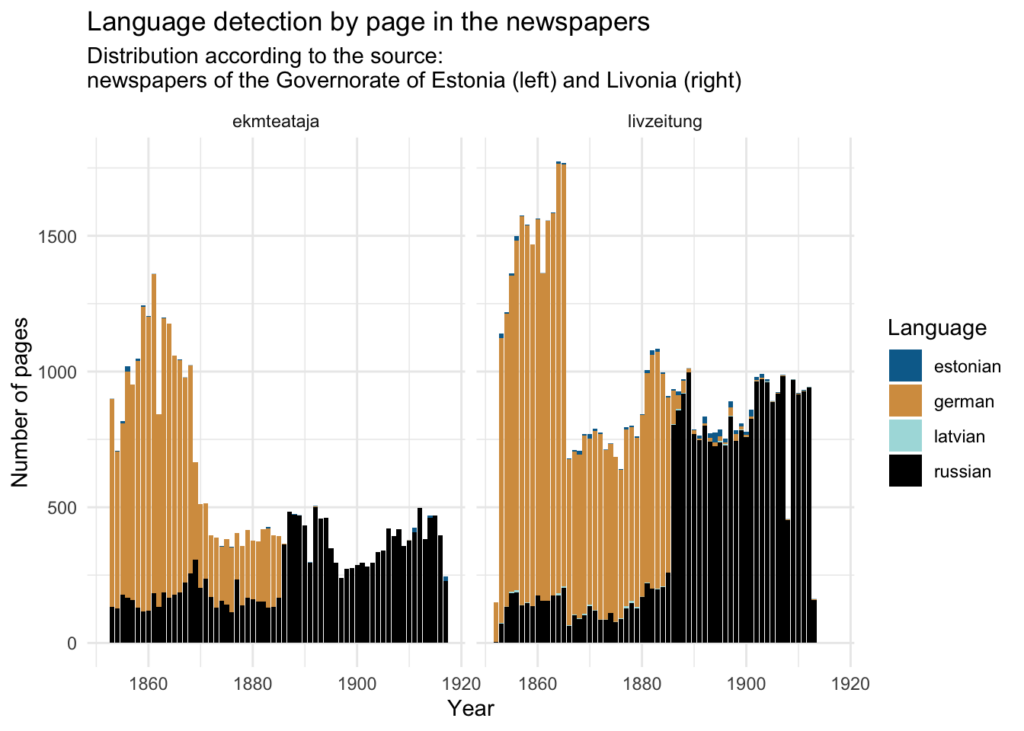
However, the number of pages in German looks very different from the distribution of words in this language gathered from sections. This can be connected with the change of newspapers physical format from smaller to bigger pages and from bigger to smaller font sizes towards the end of the 19th century. Distribution of number of words on pages by decades proves the idea (as there are no physical description of pages in the metadata).
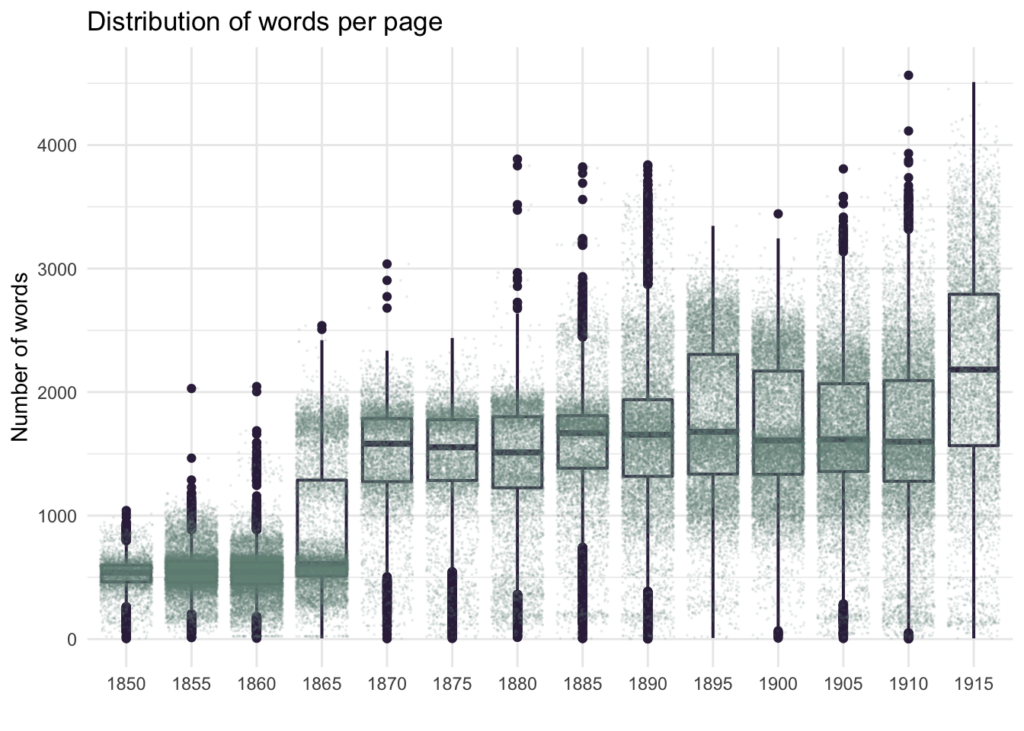
Section-based analysis thus showed more reliable results, reflecting not only the language use in the newspapers, but also some physical properties of the newspapers, such as page or font size changes over time. The plot shows how number of words per page changed in the second half of the 1860s and then remained more or less stable, so that higher number of pages in German in the 1850s and 1860s counter intuitively witness smaller amount of text per page.
Additionally, the OCR accuracy dependence on the language can be checked on the level of sections.
Cite the blog post:
Martynenko, Antonina 2022. Languages in DEA newspaper collection 1850-1918. Eesti Rahvusraamatukogu digilabori juhtumiuuringud. DOI 10.17605/OSF.IO/CPQ2W.
Data and code are available here: https://doi.org/10.17605/OSF.IO/CPQ2W.
The study has been made as part of the EKKD72 project "The usage possibilities of textual data in digital humanities case studies on the example of newspaper collections in Estonia (1850-2020)".
National Library of Estonia
Tõnismägi 2, 10122 Tallinn
+372 630 7100
info@rara.ee
rara.ee/en