Kokkuvõte
See blogipostitus uurib keelte kasutust DIGAR-i „vene“ kogus. Enne 1918. aastat avaldatud ajalehtede metaandmed viitavad suurele hulgale venekeelsetele ajalehtedele, kuid nii lehekülje-tasandil kui segmenteeritud andmed näitavad, et ajalehed ei olnud ükskeelsed ja osa venekeelseks märgitud sisust on tegelikult saksa-, eesti- ja lätikeelne. Analüüs näitab, kuidas peegeldub Eesti venestamise ajalugu digiteeritud ajalehtedes ja kuidas probleemid metaandmetega võivad mõjutada OCR-i kvaliteeti.
Metaandmete järgi on suur osa imperialistlikul perioodil (enne 1917. aastat) välja antud ajalehtedest märgitud venekeelseteks. Kui lugeda lehekülgi, peaks olema üle 120 tuhande venekeelse lehekülje (keele tulba järgi), mille ajaline jaotus on järgmine:
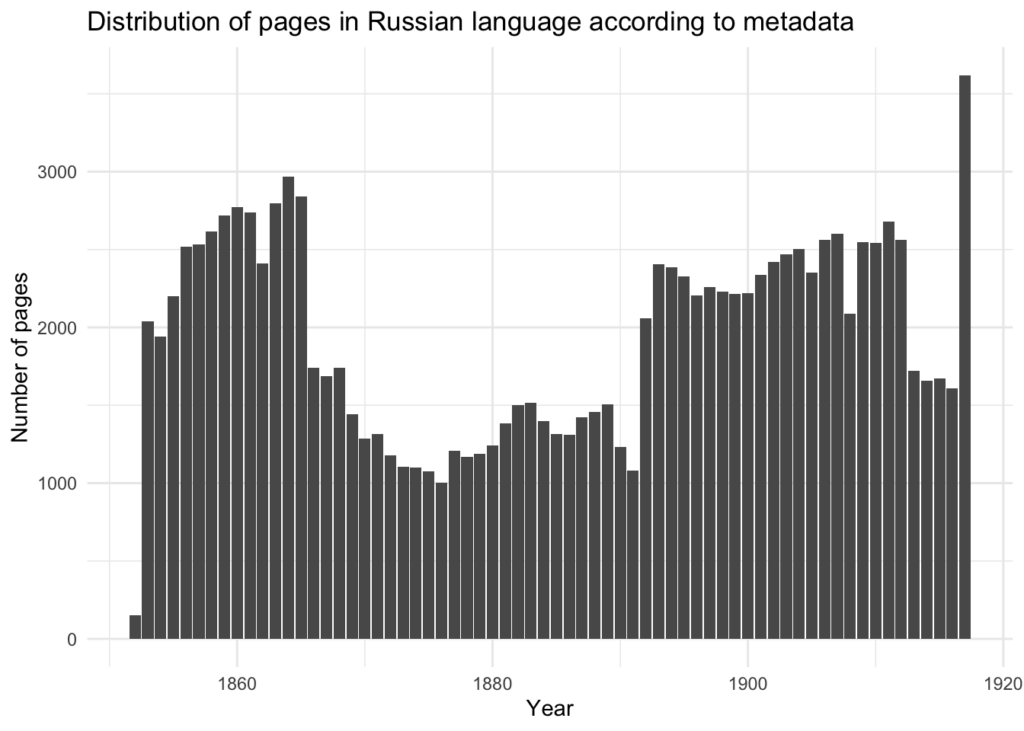
Lehekülgede tekste vaadates on ilmne, et vähemalt osaliselt on pealkirja keele metaandmed valed: näiteks varaseimad kogus leiduvad 1852. aastast pärit venekeelsed leheküljed on tegelikult peamiselt saksa keeles.
tekst
1842 sich außer der Stadtbefehlshaberschaft auch auf die Stadt Rostow (im Jekaterinoslawschen Gouvernement) erstreck. Der Procureur d’er StadtbefeHlstzaberAchOßk. d) I n Taganrog. Im Ressort des Ministeriums des Innern: Die Taganrogsche Stadtpolizei, unter der Das Polizeiwesen nicht nur in der Stade Taganrog, sondern oud) m dem dazu gehörenden Kreise steht. Die Taganrogsche Stadt-Duma. Die Taganr
0тд елъ второй. Zweite Abtheilung. Часть оффициальная. Officieller Theil. Durch Allerhöchsten Tagesbefehl im CimlRessort vom 19» October 1852, Nr. 269, sind bestätigt: Als Rigascher Ordnungsrichter Major von Tiesenhausen, der auch schon bei frühem Wahlen dieses Amt bekleidete, und als Dörptscher der im Jahre 1836 aus der 11» ArtillerieBrigade als Stabs-Capitam entlassene von Oeningen. Als Adju
Md. XIV. Ust. über Pässe und Läuflinqe Art. 589. Nr. 82. ’ Diebstahl. Publication der Strafbestimmungen für denselben. Nr. 85 u. 86, lettisch und ehstnisch Nr. 91 u. 92. Dienstboten-Bücher Nr. 54, lettisch und ehstnisch Nr. 55, deutsch, lett. und ehst. Nr. 56. Ausreichung derselben Nr. 61. Verbot aller Rügen und Bemerkungen über die Führung Nr. 78, 79, 81. Don au-Fürstentümer, vide Manifest. Dorpa
Keeletuvastus
Keelte umbkaudseks tuvastamiseks kasutati R-i teeki textcat. See võtab sisendiks teksti stringina ja tuvastab keele arvutades keskmise skoori, tulemuseks on uus metaandmete veerg, mis kajastab iga lehe kõige tõenäolisemat keelt.
Selleks võib leiduda mõni parem moodus, sest paljudel lehekülgedel võib olla mitu keelt koos. See teek on siiski piisav ligikaudseks keelte osakaalu hindamiseks.
textcat'i keeletuvastus pole täiuslik, tuvastatud keelte kogu andmestik näitab, kuidas madala kvaliteediga OCR mõjutab tulemusi. Mõned leheküljed märgiti keelega, mida Eesti ajalehtedes tõenäoliselt ei esinenud, näiteks nepaali või indoneesia keel. Vähemalt 150-s leheküljes esinenud keelte jaotus on järgmine:
##
## estonian german latvian russian ukrainian
## 699 49328 128 74815 3102Tegelikult tuleks analüüsist välja jätta ka ukrainakeelsed lehed, kuna tegemist on vigaselt tuvastatud kirillitsaga. Juhuslikult valitud lõigud näitavad, et need lehed on enamasti vene keeles, kuna kõiki pole võimalik kontrollida, filtreerisin need lehed välja, märkides need segasteks ja ettearvamatuteks. See tulemus valmistab pettumust – see ei näita keelelist mitmekesisust, vaid pigem viitab probleemsetele tööriistadele, mis on treenitud levinud keelte põhjal, ning väljendab imperialistlikku suhtumist, et ukraina keel (tähestiku poolest) on segane kirillitsa, mis pole vene keel (vt näidet allpool).
tekst
4 Р е в е л ь о x I н fl I :i lotis. M 259 О К Ъ Я В Л К П I я. отъ эстляндской КАЗЕННОЙ ПАЛАТЫ ОБЪЯВЛЕНИЕ. Уъзлнын Казначейства Везенбергское. Вейсенштейнское и Гапсальское, Эстляндской губернш, будутъ производить съ 1-го января 1897 г. слЬдующш байковый oiiepuuiii: 1) размъпъ денегь крупныхъ кредитных!, билетовъ на мелка*, мелкихь на крупные и ветхнхъ на годные къ обращешю; 2) покупку бнлетовъ
Ui urm paifUiitMB, t. Рмш, 87-y, urym 1900 ff. Пив11я1Йи|ц ■—ууп. ТамграфЫ (umt;.r«aib«aia Uua.-«iB’. 4 Р в в е ль oxl а И tat о! а. «19: ОБЪЯВЛЕН! Я. Упраие ul’ BajTlBcKol и Вомм-Тижгко! жмЪшъиъ дорогъ >тр» Вслв »» n npun торги» nnrimiiM « »yxert ар.ххож-«о «kau porno »kau. TO. »a oceoaaaia jj 11 oaaaomuik MpaaaJV будет» арогааеде» ifrjiufuol «tau ТО», pork - 14 Дгаавра IMI r. i баг
Рмми F tr« И »»HlUi Б Ъ М R .1 В В I Г М 246. •а j О .•га ИЯИИНДЙЙИКЯКЙКиц ДДЙЙЙЙЙЙ Д и м£Д Я KjlH И Н Д Д Н Н Н Н И И Н Ц U К|Д Ц|Ц ИДИ Н.ЙДЙ ДЙ ДЙЙЙЙ я ОТКРЫТА ПОДПИСКА ЗЩГ на 1894 годъ ““W>’ на егедиеввую газету мЪстныхъ интересовъ, литературную и политическую „РевеjbCKifl lüitem“ Подл. цна: съ Перес, и дост. на 1 годъ … & руб. — коп. » » » т 6 м*сяцевъ . Q » — » » » » на 3 » .
Kui jätta välja ukraina keel, annab textcat keeletuvastus meile järgmise keelejaotuse:
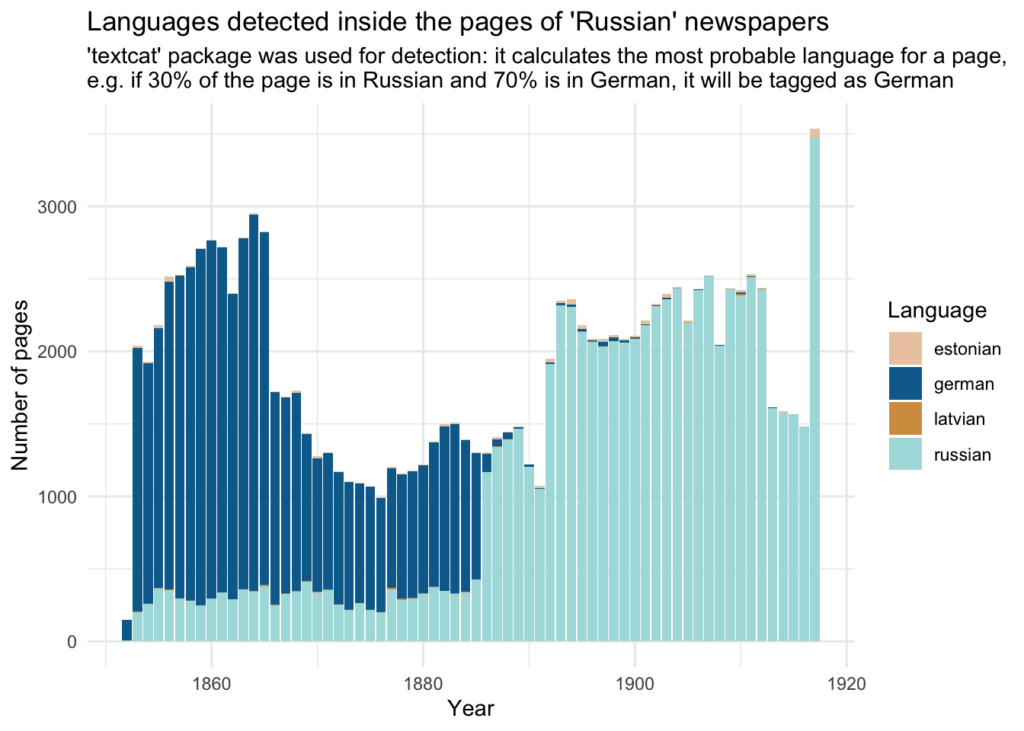
Usun, et see tulemus on märkimisväärne, sest see näitab selgelt, et osa vene keelseks märgitud 19. sajandi ajalehtedest tuleks ümber hinnata: ilmselgelt on tegu saksakeelsete ajalehtedega.
Samas tundub üleminek saksa keelelt vene keelele 1880. aastate lõpus usutav, sest 1880. aastaid tuntakse kui venestamise perioodi. Kummalisel kombel toimus see väga järsku, seega võiks uurida, kas keelevahetuse järel muutus ka oluliselt ajalehtede sisu.
Täienduseks mainin, et keeleline jaotus ei sõltu ilmumiskohast, milleks on enamasti Riia või Tallinn (Revel).
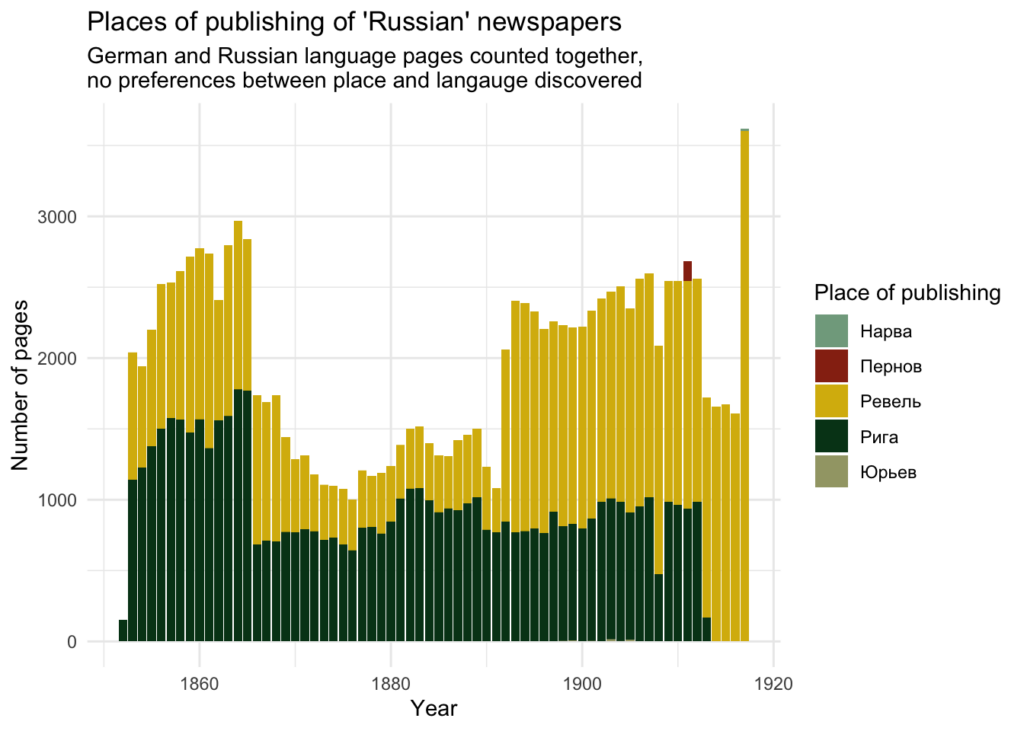
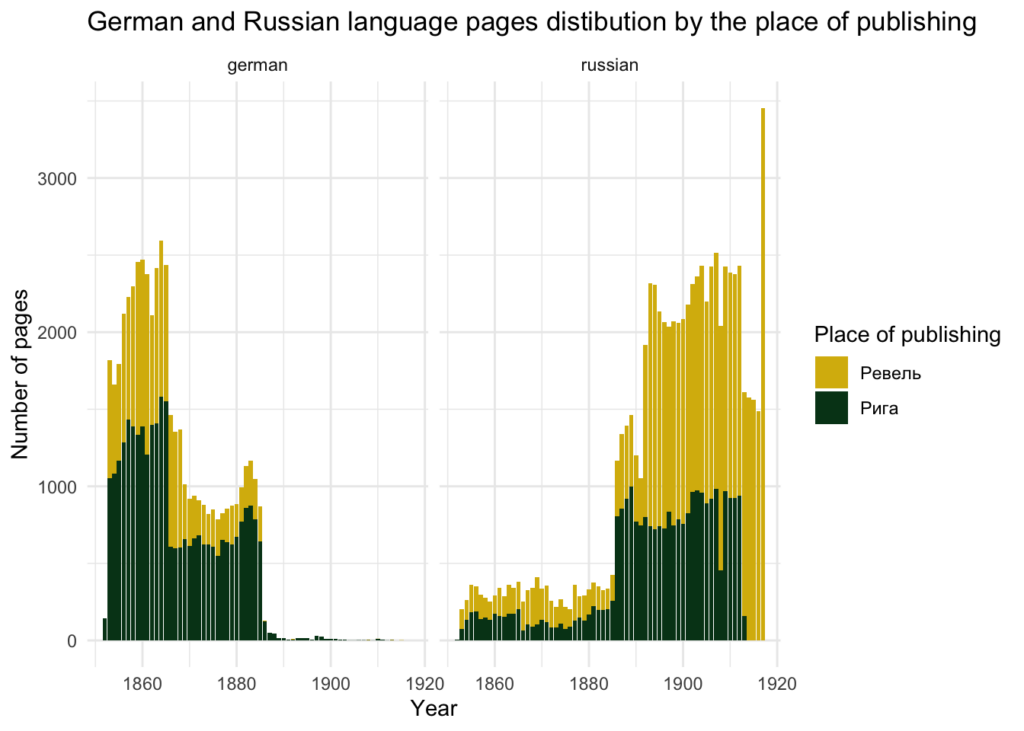
OCR-i täpsus ja keeled
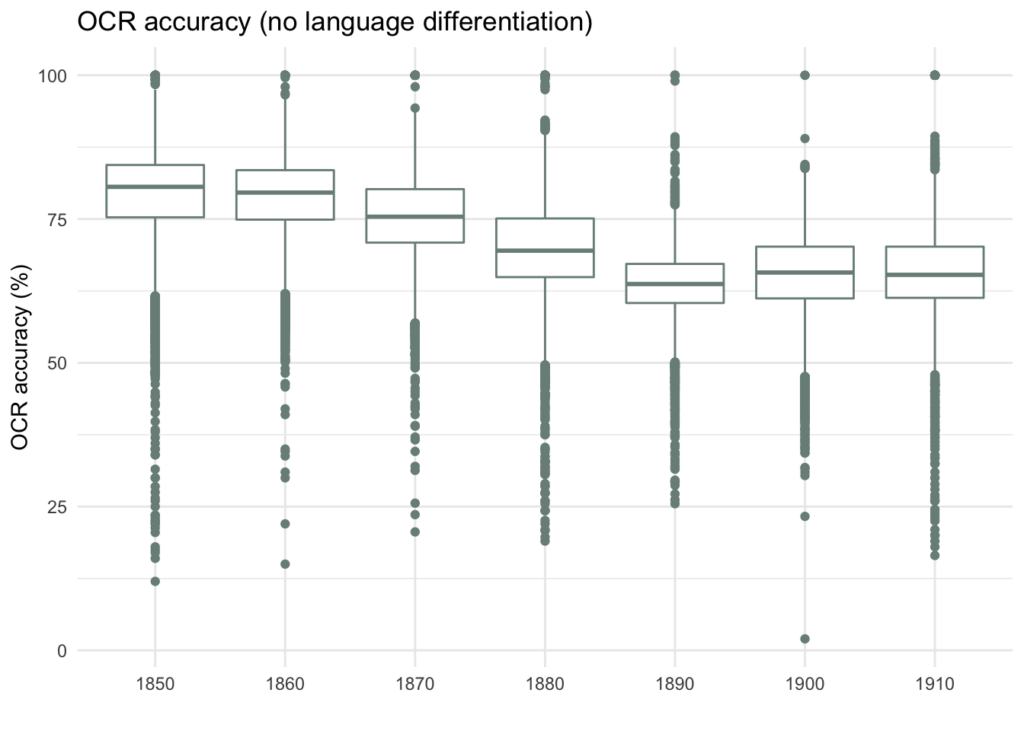
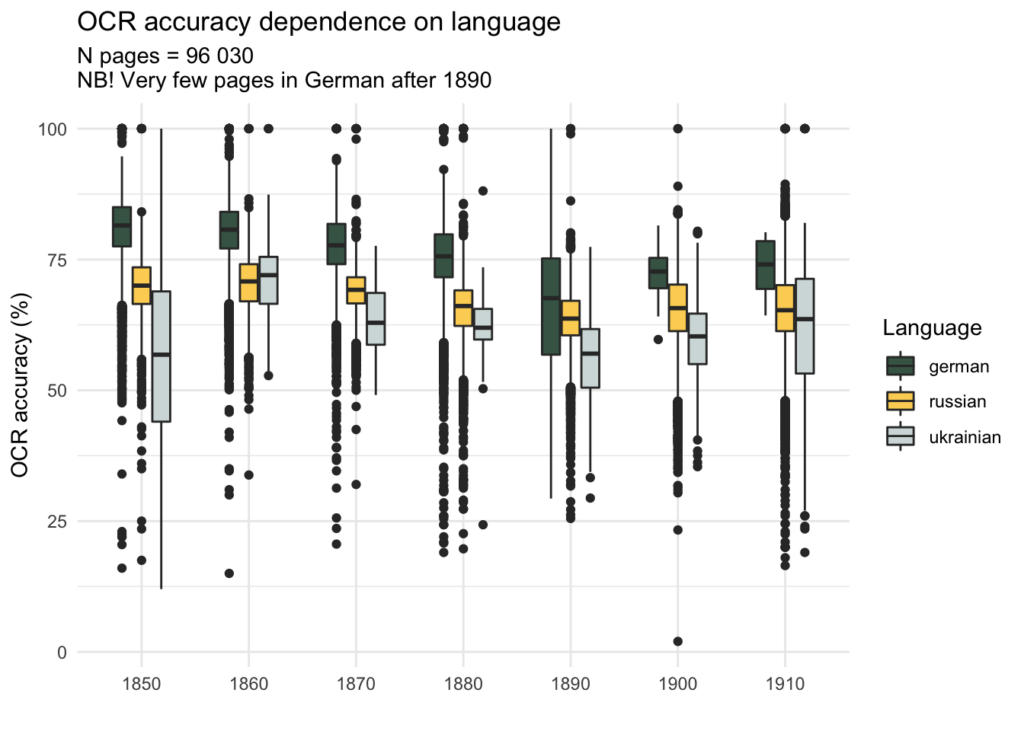
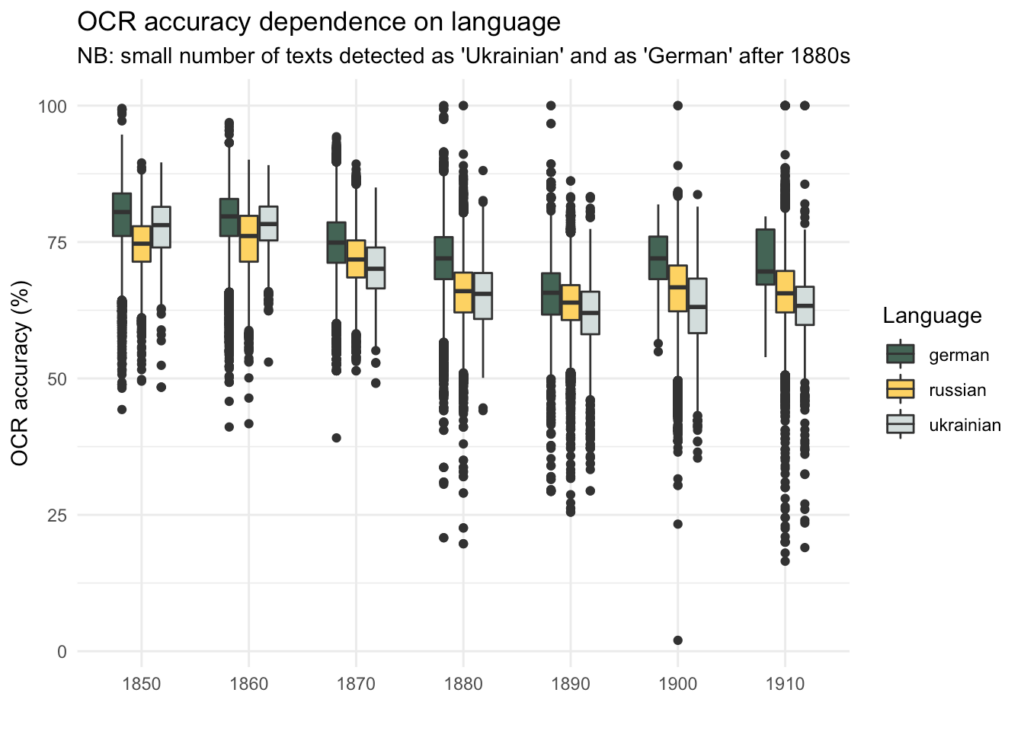
Tehnilisest küljest tundub, et metaandmetes venekeelseks märgitud keeled (või kirjasüsteemid) mõjutavad OCR-i kvaliteeti. Kui kujutada OCR-i täpsus kümnendite kaupa võib jääda mulje, et 1880-ndatel kvaliteet langes, mis võis olla tingitud venestamisest. See on aga väär, sest tegelikuks põhjuseks on OCR-i täpsuse varieeruvus saksa ja vene keele (või üldisemalt ladina ja kirillitsa kirjasüsteemide) vahel. Alltoodud graafik näitab, kuidas OCR-i kvaliteet jaguneb uuendatud keelte metaandmete järgi; samuti on näha, et ukrainakeelseks märgitud lehtedel on OCR-i kvaliteet väga madal.
Kokkuvõttes on oluline ja mõistlik keele metaandmed üksikasjalikumalt ümber hinnata (nt segmentide kaupa), lisada need metaandmetesse ning seejärel koondada mitmekeelsed märgistused kogu ajalehe keeleandmete kogumiseks.
Aruanne uuendatud: 10/11/2022
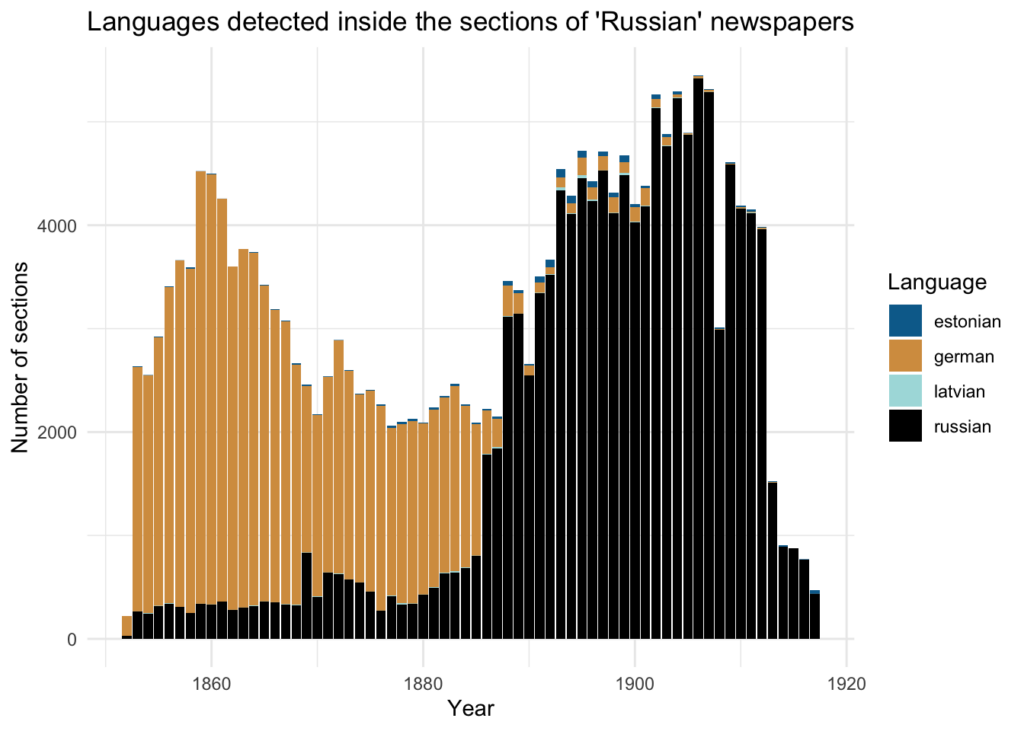
Ülaltoodud tekst näitas erinevust pealkirja metaandmete ja tegeliku keelekasutuse vahel ametlikes ajalehtedes kogus: kuigi ajalehed on märgitud venekeelseteks, võib digiteeritud materjalidest järeldada, et suhtluskeelena kasutati valdavalt saksa keelt kuni 1880. aastate keskpaigani. Analüüsiti lehe kaupa, määrates kasutatud keelte osakaalu ja märkides iga lehekülje kõige tõenäolisema keelega. Tulemusi saaks parandada, kui kasutada sisendandmetena kogu lehe asemel ajalehe segmente ehk sektsioone, kus iga sektsioon on tõenäoliselt ühes keeles kirjutatud.
Selle aruande uuenduse eesmärk on demonstreerida segmenteeritud teksti keeletuvastuse tulemusi. Kuna segmenteeritud andmed on hetkel saadaval vaid kahel ajalehel, ei saa allolevaid tulemusi võrrelda kogu korpuse analüüsiga (segmendid on saadaval vaid Eesti ja Liivimaa ametlike ajalehtede jaoks, andmestikus lühendatud kui ekmteataja ja livzeitung).
Segmentide keeled tuvastati paketi textcat abil nagu lehekülgede puhul.
Kümme kõige levinumat keelt on suures osas samad, mis lehekülgede korral; väikeste segmentide puhul on veaoht suurem (eriti kui tekst sisaldab vähem kui 20 sõna).
| language | n_sections | percentage |
|---|---|---|
| russian | 126937 | 56.84 |
| german | 83578 | 37.42 |
| ukrainian | 6257 | 2.80 |
| english | 1495 | 0.67 |
| estonian | 1299 | 0.58 |
| bulgarian | 1078 | 0.48 |
| middle_frisian | 886 | 0.40 |
| rumantsch | 305 | 0.14 |
| latvian | 290 | 0.13 |
| belarus | 276 | 0.12 |
Balti ajalehtede puhul ootamatud keeled nagu inglise, bulgaaria ja romanši osutusid tuvastusvigadeks, mis tekkisid lühikeste ja madala OCR-i kvaliteediga lõikude tõttu. Kahjuks, nagu ka lehekülgede puhul, on ukraina ja valgevene keeled samuti tõenäoliselt tuvastusvead, mille põhjuseks on kehv OCR ja/või treeningandmete puudumine nende keelte tuvastamiseks. Allpool on toodud juhuslikult valitud näited iga valesti tuvastatud keele kohta.
| lang | text |
|---|---|
| belarus-windows1251 | ZiüMv-ZlonnW Нар. изд. Я. Верм ана. Для ознакомлешя одна км. высыя. беаалатнв. Сяб.. Фонтанна ?j. |
| bulgarian-iso8859_5 | Став Отправлешя. ц i в: Нааначен1я. накладных^ Время отправления. Отправитель. Получатель. Родъ товара. ВЪсъ. II. Ф. Цвинскъ Модонъ 5043 15 сентября Хаймъ ВалПредъявит. Веревки . . . 5 05 1903 г. лерн!тейнъ дубликата Шпагать пеньковый …. 2 20 Рига тов. Модонъ 92243 13 сентября Отокаръ Предъявит. Кондяторемя то1903 г. Войта дубликата варъ …. 8 01 Рига тов. Модокъ 92617 13 сентября Шааръ иКаПредъявит. Впно виноградное 7 — 1903 г. внцель дубликата Правлен1е . |
| english | ЧАСТЬ ОФФИЦИАЛЬНАЯ. Отделъ местный. Officieller Theil. Locale Abtheilung. |
| ukrainian-koi8_r | П ММЦШ ГЛВЯОП* ТШЮГРАФМ ( Зяьмоигх») посту лиди въ продажу отдЪаышми брошюрами; ОБЯЗАТЕЛЬНЫЙ ПОСТАНОВЛЕНЫ Рижской Городской Дупы. X. О распорядк! на Рижскихъ рынкахг. XX. Для заведений трактирнаго промысла въ город! Риг!. тгг. О содержали пиеныхг, портерныхъ и питейныхъ лавонъ, а равно ренсковыхъ погребовъ съ распивочною продажею кр!пнихг иапитковг. lüim OO коп. |
Sellegipoolest näib textcat-teegi väljund olevat usaldusväärne lõikudel, mis on märgitud läti- või eestikeelseks, isegi siis, kui segmendis on mitu keelt segamini, näiteks:
| lang | text |
|---|---|
| estonian | Kulutus. Liiwlandi Kubbernemango Wattitsus on Patenti läbbi sest 16. Oktobrist 1862, Nr. 71 ja Liiwlandi Kubbernemango Tseitungi läbbi sest 11. Aprilist 1855, Nr. 42 teada aimud, et ükspäinis Priwati- rahwas sedda makso Liiwlandi Kubbernemango Tseitungi eest Posti Kontori jures woiwad sissemaksta; agga et keik kohtud ning seadusse ammetid, kes tahtwad Kubbernemango Tseitungid piddcida, muudkui mitte mõisa- egga watta-wallitsussed ja kihhelkonnakohtud peawad maksorahhad taieste Kubbernemango Wallitsusse kätte saatma, ja et ja watta-wallitsussed ning kihhelkonna - kohtud peawad sedda makso omma kohhalisse Sittakohto jures sissemaksma. Et nüüd kül se käsk sai antud, siiski on mitmel korral Liiwlandi Kubbernemango Wallitsussele teada antud, et paljo mõisad, selle assemel, et nad peaksid omma makso Sillakohta jures sissemaksma, saggedaste agga iittestumnstanud, et nemmad tahtwad sedda makso Liivlandi Kubbernemango Tseitungi wäljaandja jures stssemaksta: agga kui järrele nõutakse, kas on ka |
| latvian | !!Walmeerâ!! Preeksch wifadeem godeem peedahwa grun, tiguwihnu, konjaku. araku, ruviu. likeeruS un wisadus fchehlHinuS no teem wisslaweliateem wihna pagrabcem un spirtus destilaturahm par mehreenu zenu pee laipnigaS un labas apdeenefchanas. Pee pllnigahm eepirkfchanahm ari apfofu traukus bes kahdas atlihdsinafchanaS aisdot. R. W. Müller, materialu- un perwju bode, wihna- ua fpirtus kantoris. Bijuschä meesneeka Zack k. namä Rr. 90. P. Schilling’« un jitäs grahm. bodes dabujama fchahda eewehrojama grahmata: Kreew« - Tnrku kara-krouika 1877 un 1878. Pehz kcna-prateju un wehsturigahm fi«ahm fastahdijis LapaS Mahrti«fch. Schis pilnigais pehdeja kara apraW tfnahks 10 lihds 12 burt» ntzkS ar flawenu generalu un diplomatu bildehm (katra burtnize ir dtwi bildes). 8 burtnizeS Ir jau zita» ifnahkS drihfä laikä. Kurfch wisaS burtnizeS buhs pirziS, dabuhs par prehmiju teetu j auku bildi „Kautinfch pee Schipkas grawaS”” partikai 25 kap. (Tchi bilde roifu raafaff 1 rbl. 25 kap.) Tas no wiseem labp |
Valides ainult venekeelsed, saksakeelsed, eestikeelsed ja lätikeelsed segmendid, on keelte jaotus järgmine:
Segmentide ja sõnade arv keelte lõikes:
| Language | Newspapter | N sections | N words |
|---|---|---|---|
| estonian | ekmteataja | 405 | 143706 |
| estonian | livzeitung | 894 | 780308 |
| german | ekmteataja | 28797 | 12644769 |
| german | livzeitung | 54781 | 30316848 |
| latvian | livzeitung | 290 | 180542 |
| russian | ekmteataja | 35204 | 23334143 |
| russian | livzeitung | 91733 | 36699193 |
Kuna segmendid on erineva pikkusega, on võimalik, et segmentide loendamine (eelmine graafik) ei peegelda tekstides kasutatud keelte tegelikku osakaalu. Seda oletust saab testida segmentide sõnade arvu põhjal (metaandmetes LogicalSectionTextWordCount). Eeldame, et üks segment on enamjaolt kirjutatud ühes keeles (seega ei ole sama meetod lehekülje-tasandil rakendatav). Tulemuseks saadud jaotus sarnaneb eelnevalt väljatoodud segmentide arvule.
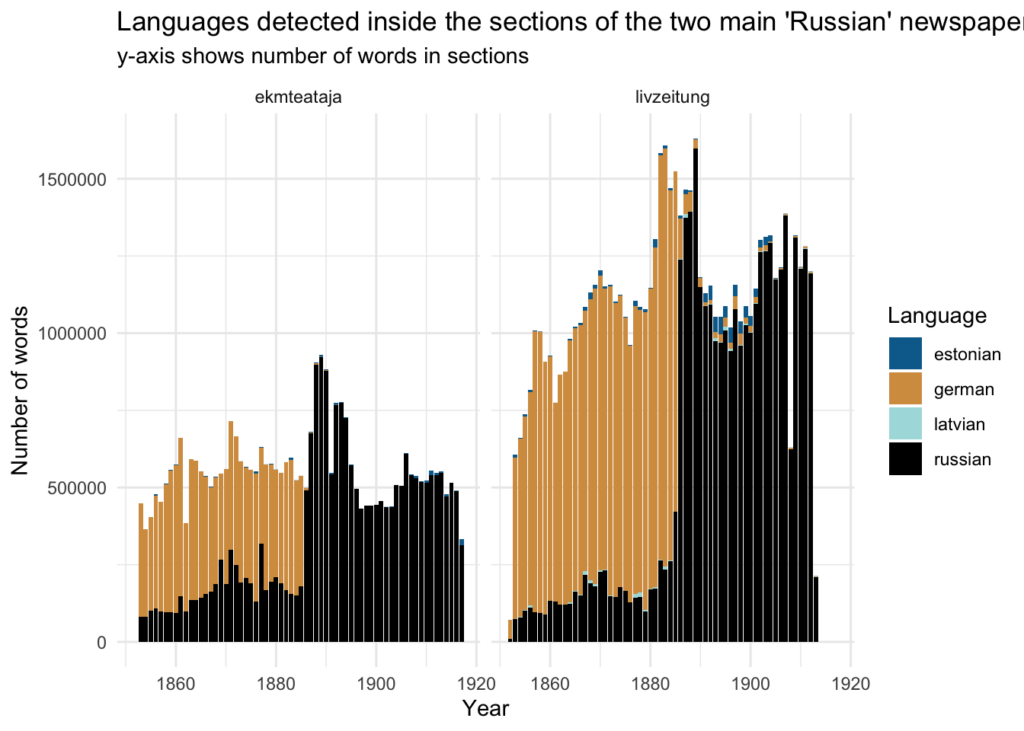
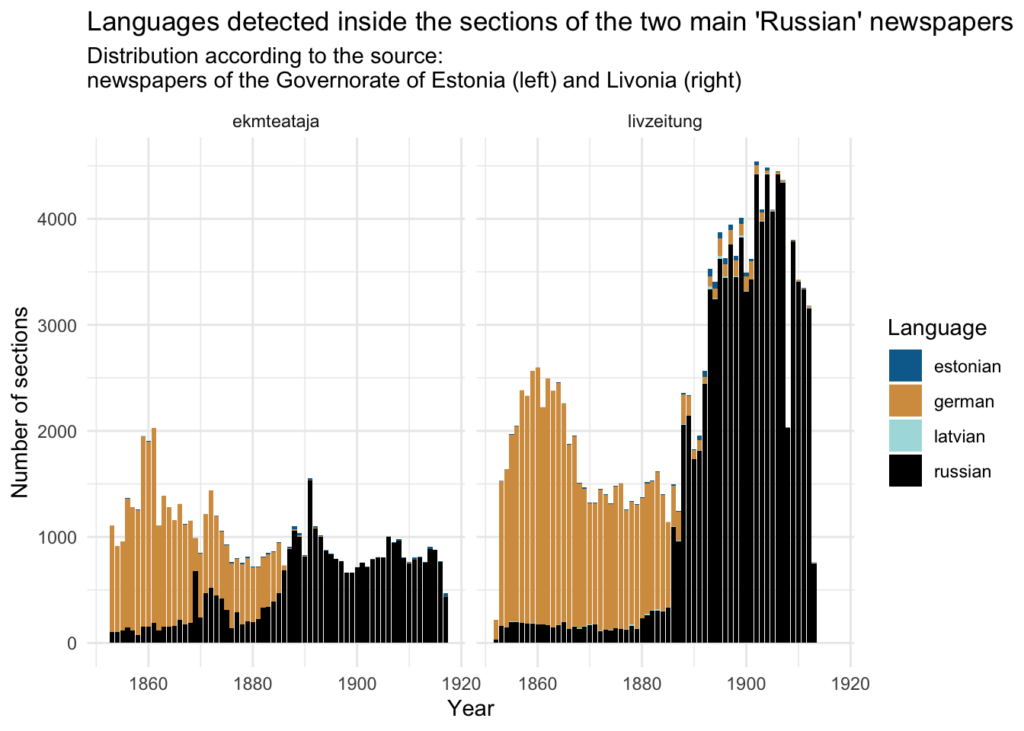
Lehekülje kaupa tuvastatud keeletega võrdlemiseks saab eelnevalt kogutud andmetest filtreerida välja ainult ekmteataja ja livzeitung (salvestatud faili data/01_pages_meta_rus_lang.csv). Üleminek saksa keelelt vene keelele ja üldine osakaal tundub segmentide puhul olevat enamjaolt sama kui lehekülgede puhul.
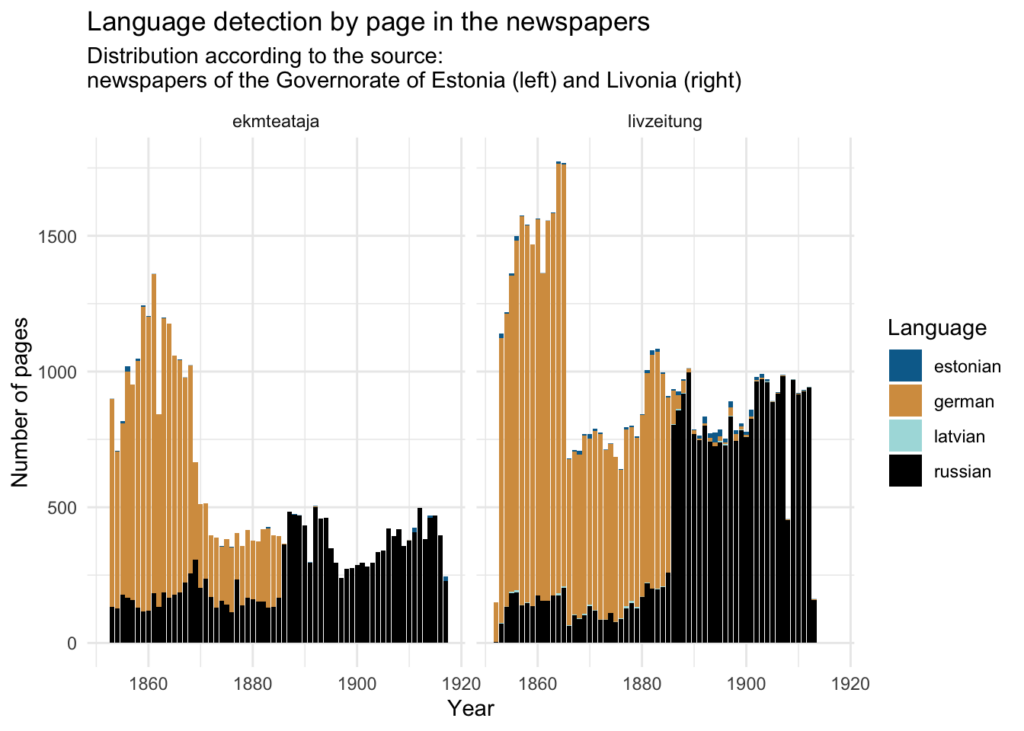
Siiski, saksakeelsete lehekülgede arv erineb oluliselt segmentide põhjal kogutud sõnade jaotusest. See võib tuleneda ajalehtede füüsilise formaadi muutusest 19. sajandi lõpul, kui võeti kasutusele väiksemad leheküljed ja väiksem fondi suurus. Sõnade arvu jaotus lehtedel kümnendite lõikes kinnitab seda (metaandmetes puuduvad lehekülgede füüsilised kirjeldused).
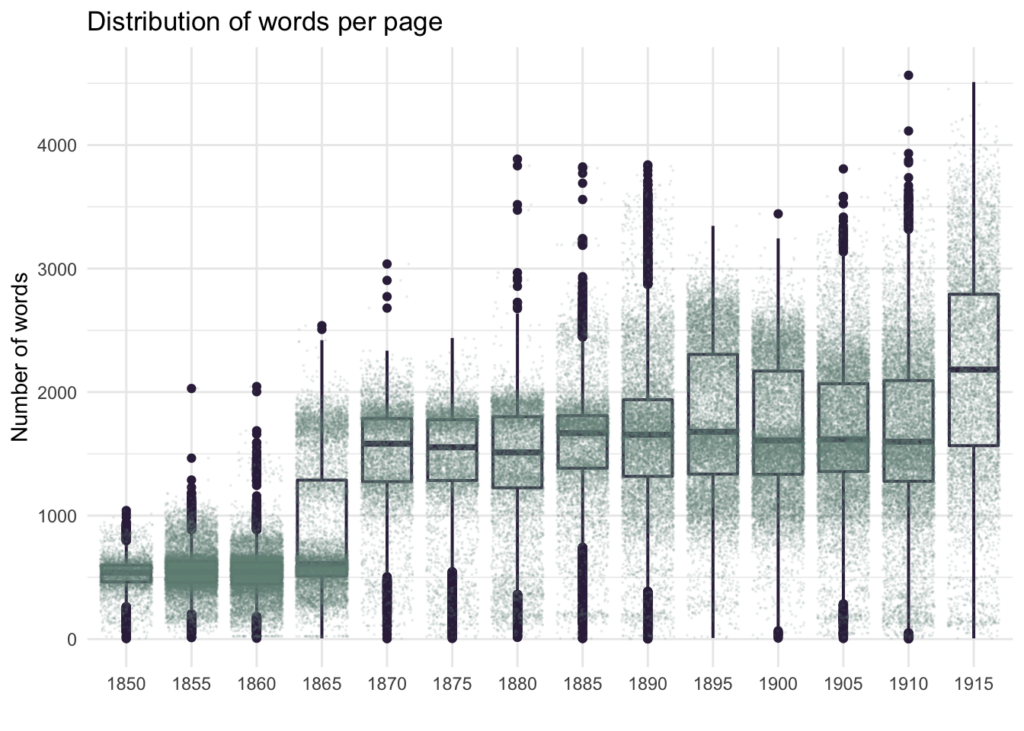
Seega olid segmenteeritud andmete analüüs tulemusrikkam, peegeldades mitte ainult keelekasutust ajalehtedes, vaid ka füüsilisi omadusi, nagu lehekülgede ja fondi muutusi ajas. Graafikul on näha, kuidas sõnade arv lehekülje kohta muutus 1860. aastate teisel poolel ja seejärel jäi enam-vähem muutumatuks, mistõttu suurenenud saksakeelsete lehekülgede arv 1850.–1860. aastatel osutab hoopis lehekülje tekstimahu vähenemisele.
OCR-i sõltuvust keelest saab kontrollida segmenteeritud andmetel.
Viita postitusele:
Martynenko, Antonina 2022. Languages in DEA newspaper collection 1850-1918. Eesti Rahvusraamatukogu digilabori juhtumiuuringud. DOI 10.17605/OSF.IO/CPQ2W.
Andmed ja kood on saadaval siin: https://doi.org/10.17605/OSF.IO/CPQ2W.
Uurimus on osa projektist EKKD72 "The usage possibilities of textual data in digital humanities case studies on the example of newspaper collections in Estonia (1850-2020)".
Eesti Rahvusraamatukogu
Tõnismägi 2, 10122 Tallinn
+372 630 7100
info@rara.ee
rara.ee