Blogipostitus on valminud Loore Lehtmetsa ja Mari-Anna Meimeri bakalaureusetöö „Ajalooliste eestikeelsete OCR tekstide järeltöötluse ja hindamise automatiseerimine Eesti Rahvusraamatukogu jaoks“ põhjal.
Taust
Oluline samm kultuuripärandi pikaajaliseks ja turvaliseks säilitamiseks on ajaloolise ainese digiteerimine. Selleks, et tuvastada digiteeritud materjalist (näiteks raamatutest ja ajalehtedest) sõnu, numbreid ja muid sümboleid, on RaRa kasutanud erinevaid optilise tekstituvastuse ehk OCR-i (Optical Character Recognition) tööriistu. Need tööriistad, mida sageli nimetatakse ka mudeliteks, võivad aga teha vigu, mistõttu ei pruugi tuvastatud tekst vastata üks ühele algses dokumendis kirjutatuga.
Ajaga on RaRa-s kasutatavate OCR-mudelite sooritus paranenud ja vigade arv tuvastatud tekstides vähenenud. Siiski leidub digitaalarhiivis veel rohkelt tekste, mis on tuvastatud vanemate mudelitega ja seetõttu leidub seal ebatäpsusi. OCR-i kvaliteeti võib mõjutada ka originaaldokumendi kvaliteet ise, näiteks põhjustavad ajalooliste tekstide puhul enim vigu laiali valgunud tint, keerulised fondid ja kulumisjäljed. Meie töö eesmärk on välja selgitada, kas ja kui täpselt on võimalik tuvastada OCR-i tehnoloogiast tekkinud vigade arvu tekstis. Selline lahendus aitab vähendada digitaalarhiivis tekstide sorteerimiseks ja filtreerimiseks vajaminevat ajakulu.

Hetkel ei ole RaRa-l täielikku ülevaadet, milline on digitaalarhiivis olevate tekstide OCR-i kvaliteet. Varasemalt on valitud tekstide kvaliteeti hinnanud tehisaru mudeliga ChatGPT-4o mini RaRa andmeteadlane Krister Kruusmaa. Paljude keelemudelite, nende hulgas GPT, kitsaskohaks on aga eestikeelsete tekstide töötlemine ning grammatikareeglitest kinnipidamine. Eriti tekitavad probleeme vanema keelekasutusega tekstid, kus näiteks v-tähe asemel on kasutusel w-täht või lauseehitus erineb tänapäeval levinud kirjapildist. Kommertsmudelite kasutamine võib suure hulga töödeldavate tekstide puhul olla rahaliselt kulukas, lisaks on märkimisväärne osa RaRa materjalist piiratud autoriõigusega, mistõttu ei tohi seda kommertsmudelitele sisendiks anda.
Meile teadaolevalt on Kruusmaa Eestis ainuke, kes on OCR-tekstide kvaliteeti hinnanud. Ka mujal maailmas on OCR-tekstide kvaliteedi hindamine vähe levinud ning peamiselt keskendutakse vigade parandamisele. 2022. aastal avaldatud artiklist (Booth jt.) selgub, et piiritletud ajastu ning temaatikaga tekstikogumit kasutades on võimalik treenida hindamismudel, mis suudab tuvastada hea OCR-i kvaliteediga tekstid ka suure hulga kõikuva kvaliteediga OCR-tekstide seast1. 2022. aastal uuris Luksemburgi raamatukogu võimalikke lahendusi OCR-i kvaliteedi hindamiseks, võttes osaliselt arvesse ka uue OCR-mudeli võimekust. Nende soov oli seda kasutada tekstide leidmiseks, mida oleks vaja ja võimalik uuesti OCR-i tehnoloogia abil töödelda. Nad ei kasutanud hindamiseks keelemudelit, vaid hoopis traditsioonilisi masinõppe tehnikaid ning hindasid enda tulemusi edukaks2.
Töö sisu
RaRa jaoks töötasime välja kaks erinevat mudelit – esimest tüüpi mudel hindab nii algse OCR-mudeliga tuvastatud kui ka parandatud tekstide kvaliteeti, teine mudel keskendub aga OCR-tekstide parandamisele. Valminud mudelid ja nende kirjeldused on leitavad RaRa digilaborist.
Keelemudelite treenimise ehk peenhäälestamise käigus näidatakse olemasolevale mudelile, kuidas lahendada teatud tüüpi ülesandeid – mudelile antakse ette näited küsimustest või ülesannetest (juhised/viibad/sisendid ehk prompt’id) ja ootuspärastest vastustest. Nii õpib mudel vastama soovitud viisil. Peenhäälestamiseks kasutame eestikeelsete andmete peal treenitud Llama-2 vestlusrobotit, mille avaldasid Tartu Ülikooli TartuNLP grupi teadlased 2024. aasta juunis3. Mudeli nimi on Llammas ehk eestindatud versioon Llamast.
Kõige olulisem on mudeli valimise puhul leida juba eesti keelt toetav variant, et peenhäälestamisel ei peaks alustama mudelile keele õpetamisest, vaid saaks kohe alustada kindla ülesande, siinkohal vigade parandamise, õpetamisest. Lisaks on oluline, et mudel oleks avatud lähtekoodiga, mis tähendab, et kõik saavad mudeli koodi ja treeningmehhanisme vastavalt vajadusele muuta. Kommertsmudelid, näiteks GPT, on suletud – nende sisemist toimimist, koodi ega treenimist ei ole võimalik näha. Selliseid mudeleid saab täiendada ainult teenusepakkuja kontrolli all ja tasuliselt.
Kuidas arvuliselt hinnata vigade arvu tekstis?
Kõige levinum mõõdik OCR-tekstides vigade osakaalu mõõtmiseks on CER (Character Error Rate) ehk vigaste tähtmärkide osakaal tekstis. Selle jaoks kõrvutatakse originaaltekst ja OCR-tekst ning seda arvutatakse valemiga 1, kus:
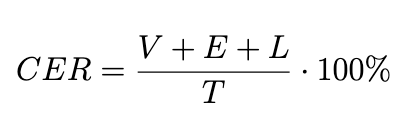
Kuigi puudub kindel mõõdupuu, mis eristaks head ja halba CER-i, siis trükitud teksti loetakse kõrge kvaliteediga tekstis, kui selle CER jääb alla 2%. Keskmise kvaliteediga tekstide CER on vahemikus 2–10% (joonis 2) ning kehva kvaliteediga tekstide CER on üle 10%4.
Andmestik
Krister Kruusmaa koostatud OCR-tekstide ja inimparanduste paaride andmestikus on 7410 teksti 179-st erinevast perioodikaväljaandest5. Keskmine sõnade arv teksti kohta on umbes 99 sõna. Kõige lühema teksti pikkus on üks sõna, pikim tekst on 3235 sõna. Vanim tekst on 1821. aastast ning kõige uuem aastast 2014. Enamik tekste jäävad 20. sajandi esimesse poolde, kus suurim osakaal on aastatel 1918 ja 1919. Neil aastatel ilmunud tekstide tuvastust parandati massdigiteerimise projekti raames6.
Andmestiku keskmine CER on 11.77%. Suurem osa tekste on CER-i väärtusega alla 20%. Kolm näidet on andmestikus ideaalse CER-i väärtusega ehk inimparandatud tekstiga samaväärsed. Halvim CER-i väärtus on 88.44%. Antud näite puhul on pea terve tekst vale, kuna inimparandatud tekst on läbivalt suurte tähtedega. Meie töö ja andmestiku kontekstis seda näidet õigeks lugeda ei saa, kuigi sisulise tähenduse poolest on see korrektne. OCR-i puhul on oluline ka originaalteksti kuju säilitamine.
Lisaks Kruusmaa koostatud RaRa andmestikule kasutame valimi suurendamiseks sünteetilisi andmeid. Selle tarvis kõrvutatakse kaks sama sisuga teksti, millest üks on ilma vigadeta ning teine vigadega. Seejärel arvutatakse iga tähemärgi tõenäosus, et see asendatakse OCR-i protsessi käigus mõne teise sümboliga7. Tõenäosuste põhjal saab tekitada vigadeta tekstidesse vigu, mis jäljendavad OCR-mudelite vigu.
Algsest andmestikust on eemaldatud kirillitsat sisaldavad tekstid ning saksakeelsed ajalehed. Eemaldatud on liiga pikad tekstid, näiteks algse andmestiku pikim tekst, mis on üle 3000 sõna, ei ole keelemudelile Llammas jõukohane, kuna maksimaalne Token’ite (1 token ~ 4 tähte) arv on 4096. Töö lõplikku andmestikku jäi alles 7146 teksti, kus kõige pikem tekst on 508 sõna ja keskmine sõnade arv umbes 90. Juhuslikkuse alusel on andmestik jaotatud test- ja treeningandmeteks. Treeningandmestikus on 5145 näidet ning testandmestikus 2001 näidet.
Probleemid andmestikuga
RaRa andmestiku suurim probleem on, et iga inimparandatud tekst ei ole tegelikult täies mahus või korrektselt parandatud. Töö käigus avastasime, et paljud inimparandatud tekstid algavad küll korrektselt, kuid poole pealt on parandamine pooleli jäänud, jättes teksti vigu. Seetõttu on 2001-st näitest koosnev testandmestik autorite poolt käsitsi parandatud. Parandamine osutus ajamahukaks, sest kohati olid testandmestikus olevad tekstid nii kehva kvaliteediga, et need olid inimsilmale arusaamatud. Selliste tekstide puhul pidime otsima digitaalarhiivist õige väljaande, sealt omakorda väljaande PDF-ist õige tekstilõigu, et vigane tekst õigeks ja algtekstile vastavaks parandada.
Keelekasutus on viimase 200 aasta jooksul pidevalt muutunud. Selle tõttu võivad andmestiku tekstid olenevalt väljaande aastast üksteisest lausestuse ja grammatika poolest märkimisväärselt erineda. Samuti varieerub keelekasutus maakonniti, seega võib sama sõna esineda andmestikus mitmes erinevas vormis. Need asjaolud muudavad hindamise eriti keeruliseks, kuna iga näite puhul tuleb kirjavigu tuvastada vastavalt kontekstile. Siin ei aita ka ajalehe nime viibas ette andmine, kuna digitaalarhiivis esinevas andmestikus on erinevaid väljaandeid palju rohkem võrreldes meie treeningandmetega, seetõttu peaks mudel ise olema suuteline vajalikku konteksti tuvastama. Lisaks sellele, et ajalooliste tekstide kirjapilt ja kvaliteet andmestikus varieeruvad, kõigub ka OCR-tekstide kvaliteet. Osade tekstide kvaliteet on väga hea ning tähemärkide vigu on vähe, samal ajal on mõni tekst ka inimsilmale loetamatu. Seetõttu võib mudeli sooritus näitest tingituna olla väga erinev.
Hindamismudeli tööpõhimõte ja tulemused
Mudelile antakse sisendiks OCR-tekst ning mudel tagastab selle eeldatava CER-i (protsendina). Eesmärk on tuvastada ja „kokku lugeda“ kõik eeldatavasti vigased tähemärgid ning arvutada nende osakaal kogu teksti pikkusest. Hindamismudelile antav viip on järgmine:
„Kui suur protsent tähemärke sellest ajaloolisest eestikeelsest tekstist on vigane? Tagasta protsent täisarvuna vahemikus 0-100. Ära tagasta midagi muud.
TEKST: {ocr_text}“.
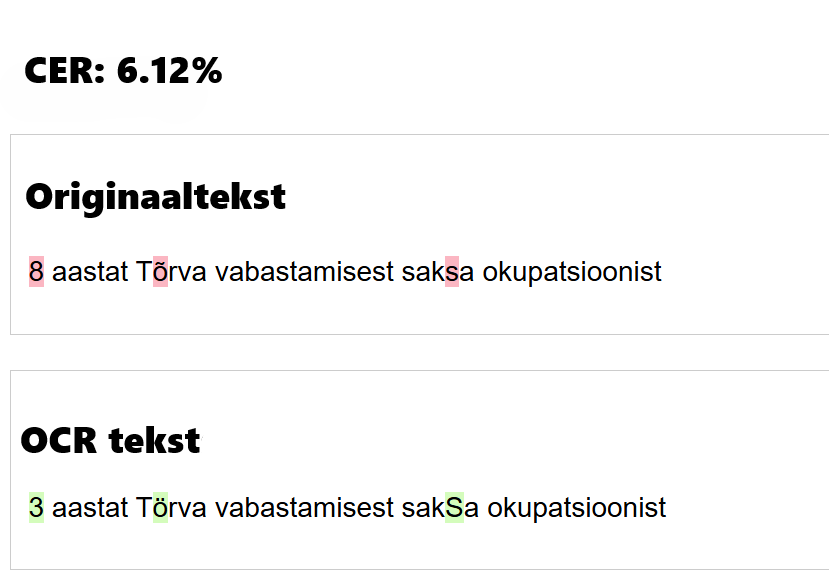
Järgnevas tabelis (tabel 1) on näited OCR-tekstidest, nende tekstide inimparandustest ning hinne, mille OCR-tekst vastavalt vigaste tähemärkide sisaldusele saab.
| Hinne | OCR tekst | Inimparandus |
|---|---|---|
| 74 | C%#tt nwlxmifli ttwlüfmtfe ajii* liite forK | Eesti wabariigi walitsemise ajutine kord. |
| 9 | «ma õpetlasele võimalust teaduslikkudeks uurimuStekS. | anna õpetlasele võimalust teaduslikkudeks uurimusteks. |
| 2 | 1. aprillist 1920. a. on Tallinna linnr piirides keelatud küpsetada ja müüa igaseltsi koolisid | 1. aprillist 1920. a. on Tallinna linna piirides keelatud küpsetada ja müüa igaseltsi kookisid |
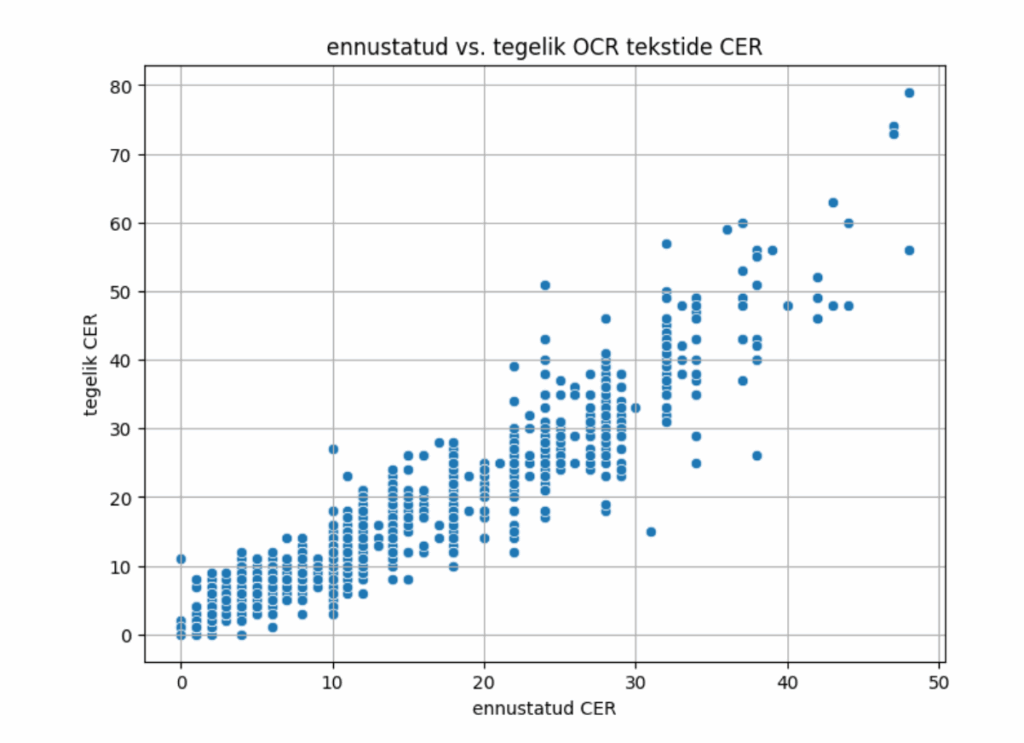
Allolev graafik (joonis 3) võrdleb meie treenitud mudeli ennustusi ja teksti tegelikku CER-i. Kuvatud on kogu testandmestiku (2001 näidet) tulemused. Kuigi mudel ei ole ennustustes alati 100% täpne, on seos OCR-teksti korrektsuse ning ennustatud hinde vahel selgelt näha.
Ennustuse ja tegeliku CER-i erinevuste analüüsimiseks on arvutatud erinevus valemiga 2. Erinevuse arvutamisel on kasutusel absoluutväärtus seepärast, et ülesande kontekstis pole oluline, kas CER-i ennustaja hindas tekstis sisalduvate vigade protsenti tegelikkusest väiksemaks või suuremaks – oluline on saada teada kõrvalekalle reaalsest protsendist.
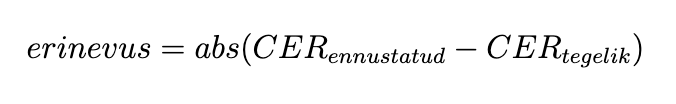
Tabelis 2 on kuvatud meie mudeli (Llammas CER-estimator) ning kommertsmudelite tulemuste võrdlused. Meie treenitud hindaja on selgelt teistest keelemudelitest parem, ühtlasi on keskmine erinevus väga hea täpsusega, täpseid pakkumisi (ennustatud CER = tegelik CER) on umbes kümme korda rohkem.
| Mudel | Keskmine erinevus | Mediaanerinevus | Täpseid pakkumisi |
|---|---|---|---|
| ChatGPT-4o | 17.40 | 13.00 | 2.15% |
| DeepSeek V3 | 13.62 | 12.00 | 1.55% |
| Llammas | 13.05 | 9.00 | 1.55% |
| Llamas CER-estimator | 2.62 | 2.00 | 19.44% |
Kokkuvõte
Peenhäälestatud keelemudel suudab edukalt tuvastada vigade osakaalu tekstis, teadmata teksti teemat, ilmumisaastat või algkuju. Töö raames valminud CER-i hindavat mudelit saab kasutada RaRa digitaalarhiivis olevate OCR-tekstide kvaliteedi hindamiseks, näiteks annab mudel väga kehva CER-i tulemusega tekstide puhul võimaluse otsustada, kas teksti parandamise asemel tuleks materjal hoopis uuesti skaneerida. CER-i hindaja abil saab kiirelt üles leida ka tekstid, mille kvaliteet on väga hea või ideaalne ning need parandamisest ja uuesti skaneerimisest eemaldada. Täpsemate tulemuste tagamiseks tuleb mudelit testida rohkemate andmetega, kuna testandmestik ei ole piisavalt ulatuslik ja varieeruv, et loodud CER-i hindavat mudelit saaks pimesi usaldada. Pärast seda saab tööriista kasutada juba kõikide võimalike OCR-tekstide hindamiseks.
Sama ülesannet on võimalik õpetada ka alternatiivsetele ja edasiarendatud keelemudelitele, et näha, kas tulemusi on võimalik saada veelgi täpsemaks. Kindlasti tasuks samu metoodikaid ja andmestikku rakendada Llammas mudelist uuema eestikeelse keelemudeli peenhäälestamiseks. Lisaks blogipostituses mainitud mudelile on lõputöö käigus treenitud täiendavad mudelid OCR-tekstide parandamiseks ning paranduste kvaliteedi hindamiseks. Lõputöö täisversiooni, töö jooksul loodud koodi, andmestike ning töö tulemusena valminud mudelitega saab tutvuda RaRa digilaboris.
Kasutatud allikad
1. Booth, C., Shoemaker, R., & Gaizauskas, R. (2022, juuni). A language modelling approach to quality assessment of OCR’ed historical text. In Proceedings of the Thirteenth Language Resources and Evaluation Conference (pp. 5859–5864). European Language Resources Association. https://aclanthology.org/2022.lrec-1.630
2. Maurer Pit Schneider, Y. (2022). Rerunning OCR: A machine learning approach to quality assessment and enhancement prediction. Journal of Data Mining and Digital Humanities. https://jdmdh.episciences.org/10239/pdf
3. Kuulmets, H.-A., et al. (2024, juuni). Teaching Llama a new language through cross-lingual knowledge transfer. In K. Duh, H. Gomez, & S. Bethard (toim.), Findings of the Association for Computational Linguistics: NAACL 2024 (pp. 3309–3325). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-naacl.210
4. Leung, K. (2021). Evaluate OCR output quality with character error rate (CER) and word error rate (WER). Towards Data Science. https://towardsdatascience.com/evaluating-ocr-output-quality-with-character-error-rate-cer-and-word-error-rate-wer-853175297510
5. Kruusmaa, K. (2024). Estonian historical newspaper crowdsourced OCR corrections [Data set]. Zenodo. https://doi.org/10.5281/zenodo.13325713
6. Eesti Rahvusraamatukogu. DIGAR Eesti artiklid. https://dea.digar.ee/?a=p&p=home&e=-------et-25--1--txt-txIN%7ctxTI%7ctxAU%7ctxTA-------------
7. Guan, S., et al. (2024, detsember). Effective synthetic data and test-time adaptation for OCR correction. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 15412–15425). Association for Computational Linguistics.
Eesti Rahvusraamatukogu
Tõnismägi 2, 10122 Tallinn
+372 630 7100
info@rara.ee
rara.ee