Summary
The simple methodological idea behind the following experiments is whether we can use topic modelling on historical OCR-ed newspaper data to spot some historical events that happened during a given period. The two periods and problems explored below are:
I - Russification in the Baltic governorates in the 1880s.
II - Reactions to two Russian revolutions in 1917.
Data
The lists of words (MFW) used for model building are available on drive. The preprocessing steps and models building showed in the notebook: github.
Russification: Switch from German to Russian in local newspapers of Governorates of Estonia and Livonia
This part of the blog post explores the switch from German to Russian language of the official newspapers of Governorates of Estonia and Livonia, shortened as ekmteataja and livzeitung respectively (the full titles are: rus. Эстляндские губернские ведомости / ger. Estländische Gouvernements-Zeitung and rus. Лифляндские губернские ведомости / ger. Livländische Gouvernements-Zeitung). As shown in the blog post on the language labeling in DIGAR collection, the digitized newspapers data shows that between 1885 and 1886 the main newspapers of the two governorates both ended to use German and started to publish texts almost exclusively in Russian. This issue will be studied below using a subset of newspaper pages and sections published in the 1880s.
Throughout the history of the two newspapers, their content was never monolingual: a proportion of German, Russian and Estonian texts can be found for the whole period under consideration. However, the severe restrictions on the language use brought by Russification can be seen in both cases by the year 1886.
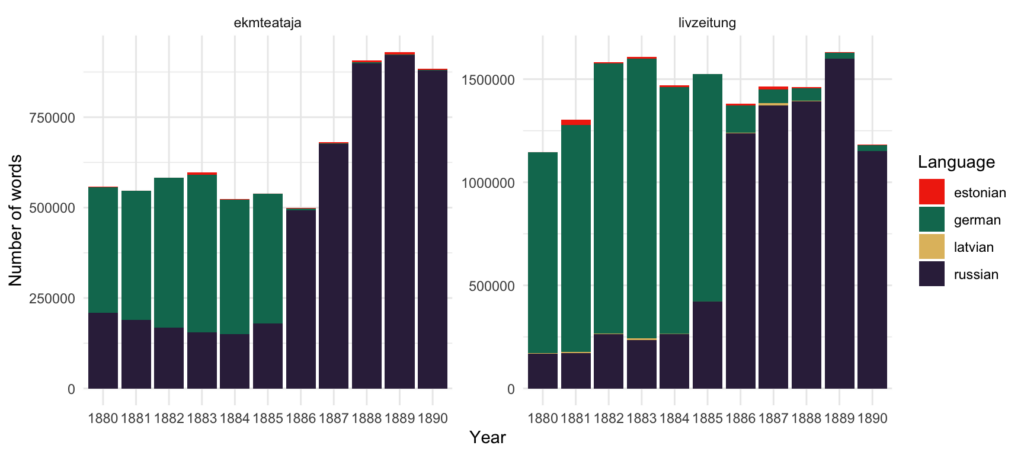
The change from predominantly German pages to Russian happened abruptly in the Estonian Gouvernorate’s newspaper (ekmteataja) in 1886 and a bit more smoothly at the same time in the Livonian Gouvernorate’s one (livzeitung). Number of sections in Estonian and Lativan can be spotted using sections data but generally the usage of both languages in newspapers stayed low in the 1880s.
For the further experiment a random sample of 3000 pages in German and in Russian was taken from the whole corpus (Estonian and Livonian newspapers mixed; see the full code in 6_np_1880.ipynb). After the selection of pages, words in texts were counted and, in the case of Cyrillic script, transformed to modern orthography and lemmatized. Transformation to the modern orthography was made with russpelling Python module (see the implementation in scr/new_ofr.py) and lemmatization for Russian performed with pymystem3 (see scr/lemmatization.ipynb).
For building the model a selection of words longer than 3 characters was used, which are not in the stoplist and appeared at least 5 times in the corpus. It results in 6745 unique words (35021 German and 52582 Russian tokens in total), 5789 documents.
An LDA model with 20 topics was built on the resulting data.
stoplist <- c("что", "это", "быть", "тот", "который", "", "они", "для", "наш",
"свой", "этот", "тот", "как", "все", "год","при", "час", "она", "есть", "чтобы",
"давать", "один", "только", "время", "кто", "так", "огь", "уже", "ваш", "сто",
"amp","под", "сие", "или", "день", "оть", "пта","январь", "февраль", "март",
"апрель", "май", "июнь", "июль", "август", "сентябрь", "октябрь", "ноябрь",
"декабрь","часть", "еще", "весь", "должный", "такой", "если", "себя", "сам",
"окт", "том", "когда", "про", "прo", "копа", "кой", "сей", "мочь", "без",
"der", "die", "das", "dem", "den", "von", "des", "werden", "auf", "bei", "und",
"mit", "vom", "zur", "uhr", "daß", "für", "zum", "sich", "wird", "welche",
"ein", "eine", "eins", "groß", "ist", "mal", "aus", "oder", "nicht", "kop",
"als","durch", "nach", "sie", "er", "es", "pfd", "bis", "per", "dito", "unter",
"mai", "aus", "allen", "alle", "alles", "thlr", "diese", "dieses", "diesem",
"diesen", "auch", "man", "sind", "ich", "nur", "einem", "wenn", "hat", "haben",
"alt","einer", "sub", "worden", "belegene", "dess", "herrn", "herr", "über",
"dieser", "aber", "nebst", "wie", "pol", "sammt", "jahr")LDA model output
Pages as documents
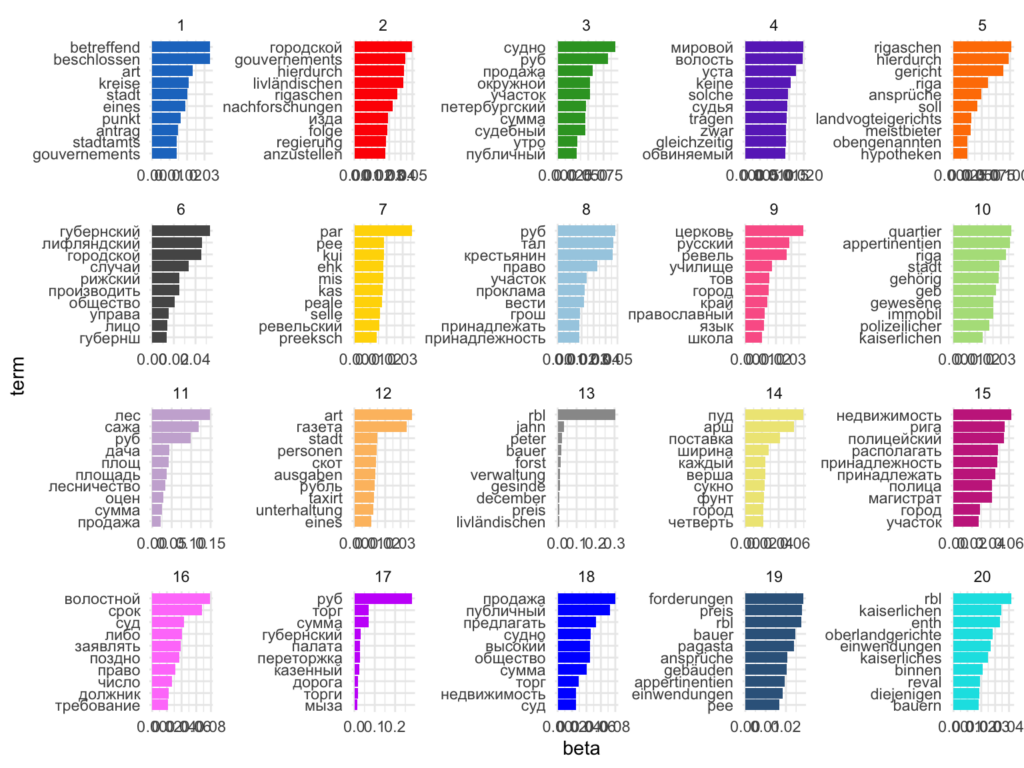
As can be seen from the most probable words in each topic, the model easily distinguishes German and Russian: see, for example, the uniquely-German topics number 7, 12, 14, and 19. Content-wise topics in German and in Russian are very similar, containing mostly words related to official news or advertisements. In both languages, the official news-related topics seem to be focused on local issues (naming places, governmental units such as magistrates and local courts), advertisements comprise words about sales, property, prices, etc.
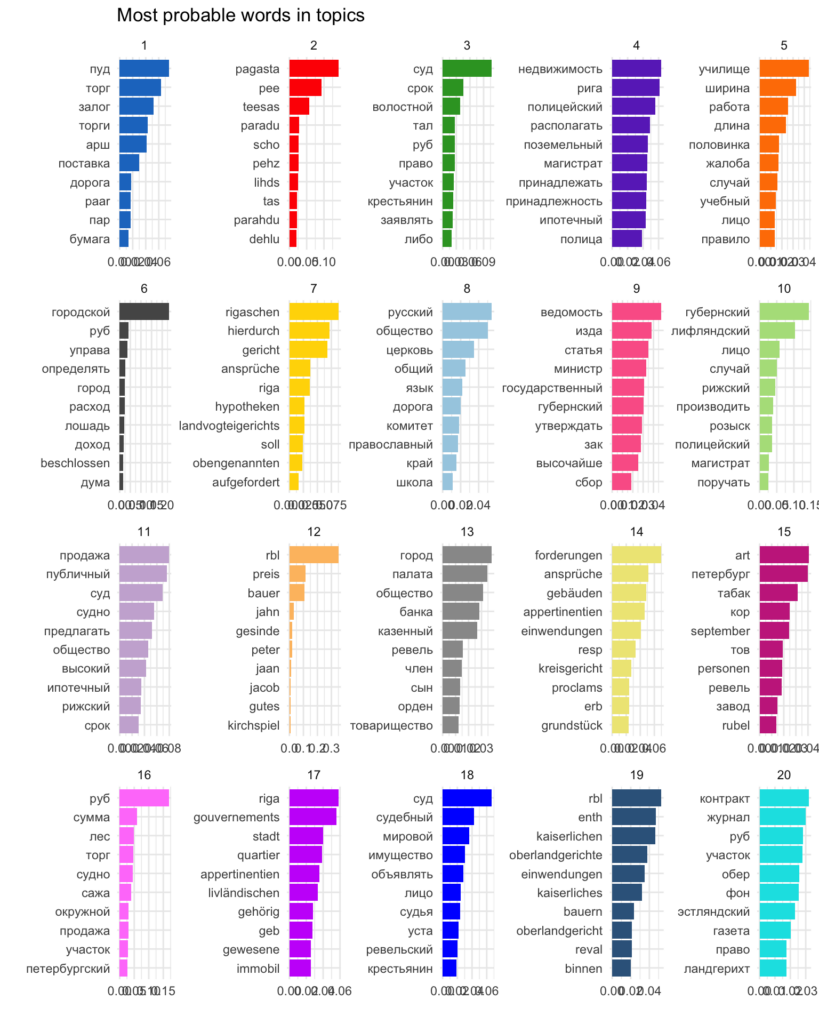
The only topic that is significantly different from the rest is the 8th that clearly belongs to ideological side of Russian politics: its most probable words are “Russian”, “society”, “church”, “common”, “language”, “path”, “committee”, “orthodox”, “region”, “school”. These are the keywords highly important for the discourse around Russification: the topic reflects an imperialistic view on the citizens of the empire as one nation (“Russian”) as opposed to minorities living in the governorates of Estonia and Livonia; as in the middle of the 19th century, the ideological support to Russification was given by the church (appearance of the words “church” and “orthodox”). The topic also refers to the language politics and education reforms in the region referring to “language” and “school”. All 10 of the most probable words of the 8th topic do not appear as the most probable in other topics.
The question is: how much is this topic visible in the corpus?
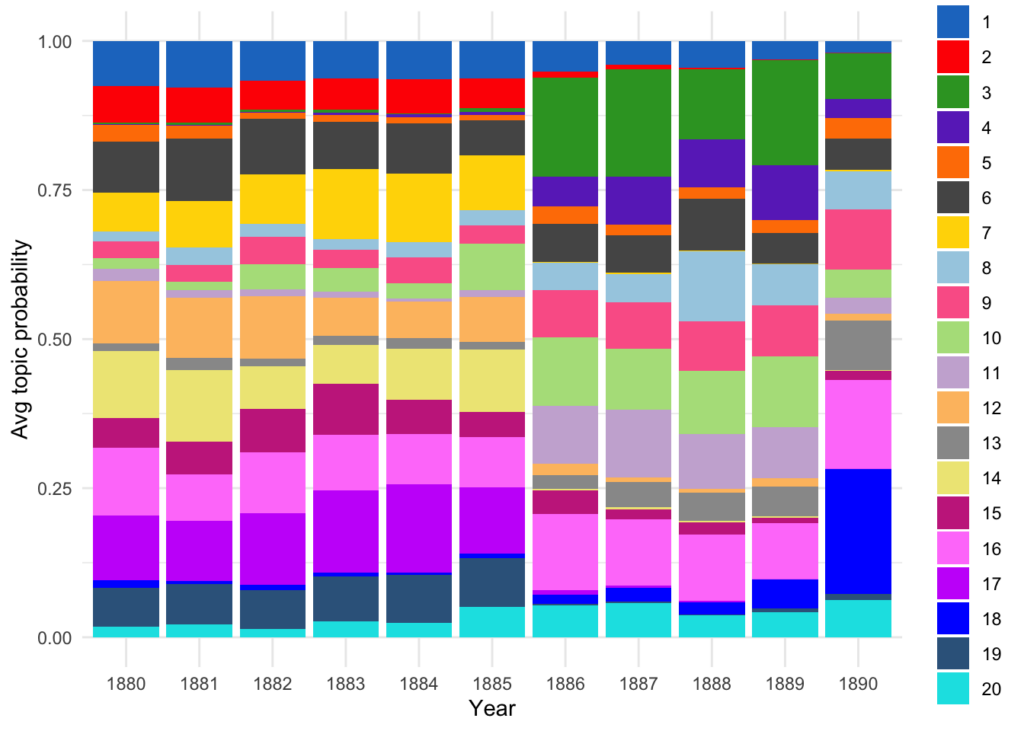
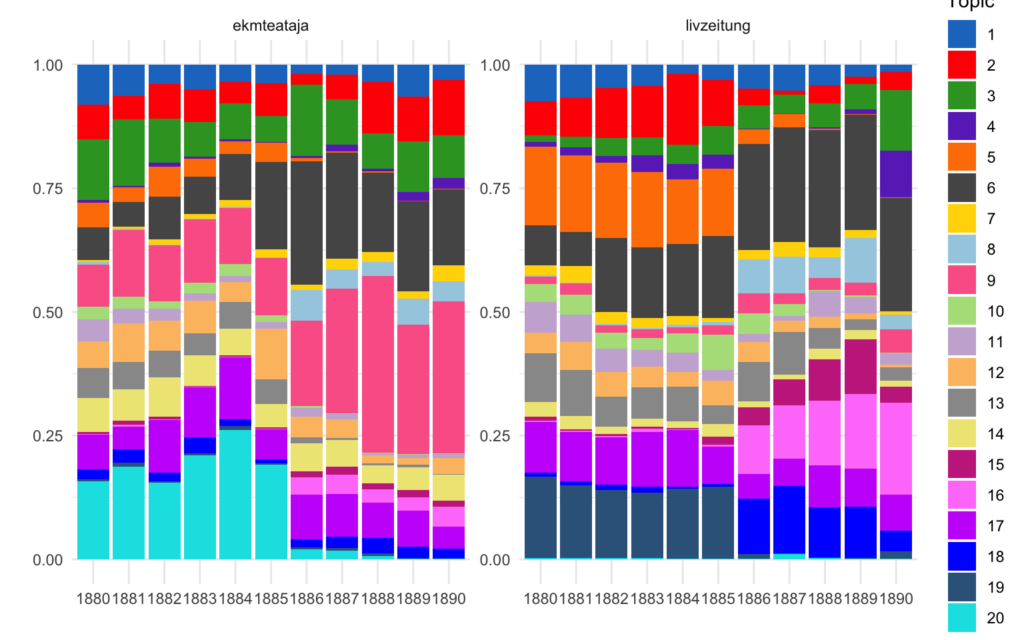
If we look at the averaged topic distribution, the general assumption to have different sets of topics before and after 1885 is confirmed: the language difference is caught by the model. The presence of topics as the 16th (Russian topic discussing money and sales of natural products) sugests that there was always some language mixing also before 1885. The topic 8 appeared unsurprisingly in 1886 and took the biggest part in 1888.
However, there is a difference in topic distribution if we take the Estonian and Livonian newspapers separately:
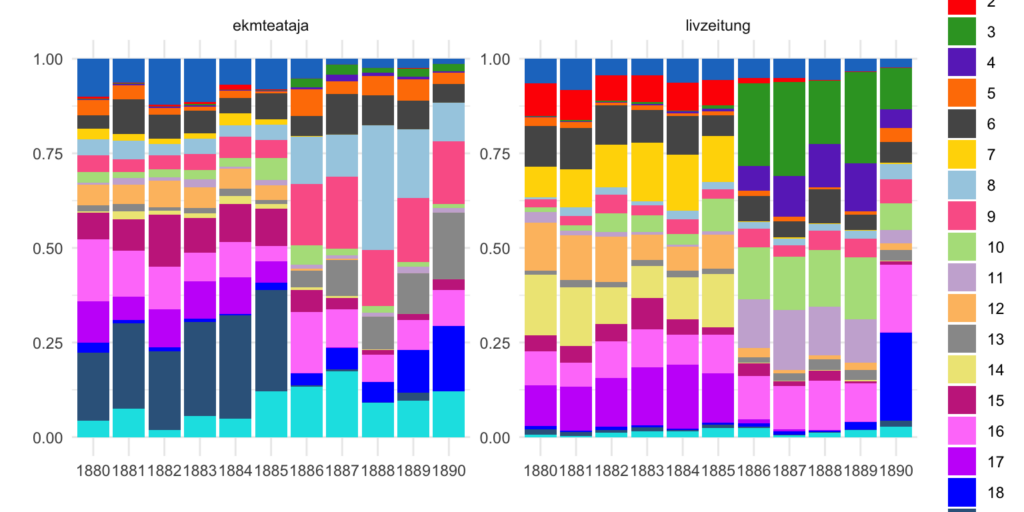
According to the random sample used, the presence of several topics are unique for the newspaper of the Governorate of Estonia, including the “ideological” topic 8. Different sets of topics appeared in the two newspapers suggesting that the content of newspapers was different despite geographical and linguistic (German-language governorates) closeness. Difference in the language use does not, however, explains why a similar “ideological” topic did not appear in Livonian governorate’s newspaper at the same time as topic 8 appears at ekmteataja.
Sections as documents
As full-pages data may be quite a noisy input for the LDA algorithm, the same experiment can be recreated using section division available both for ekmteataja and livzeitung. With sections data the full dataset available for the 1880s was used: as in case of language detection task section-based data allowed to spot sections containing Estonian and Latvian, there is also a question whether a topic model will be able to distinguish these languages from predominantly German sections. Another question to be answered is if input in sections can improve topic model output in terms of interpretation of topics in comparison with page input.
Two models were built for the experiment:
- one with the same parameters as with pages-input data discussed above (20 topics LDA model);
- another one with 50 topics which should give more granular results (50 topics model for the pages of the 1880s was less interpretable than the one with k=20 parameter, so it was not included into the report).
As might be seen from the most probable words, the 20 topics from the section-based model are quite similar to the previous one where pages were used as an input. However, section-based model were able to spot sections in Estonian and gather functional Estonian words in the topic 7. At the same time, this model gives more topics with most probable words both in German and in Russian, as one might suggest, because some sections were mixing both of the languages (e.g. topics 2 and 4).
The “ideological” topic is also appearing in this model (topic 9) with the very similar set of most probable words such as “church”, “russian”, “school”, “orthodox”, “language”. There is however a switch towards Estonian news in this topic already presented, since the word “Revel” appeared as the third most probable in this topic. The comparison of the topics distribution over time shows similar results with the page-based analysis where this topic prevalenced only in ekmteataja.
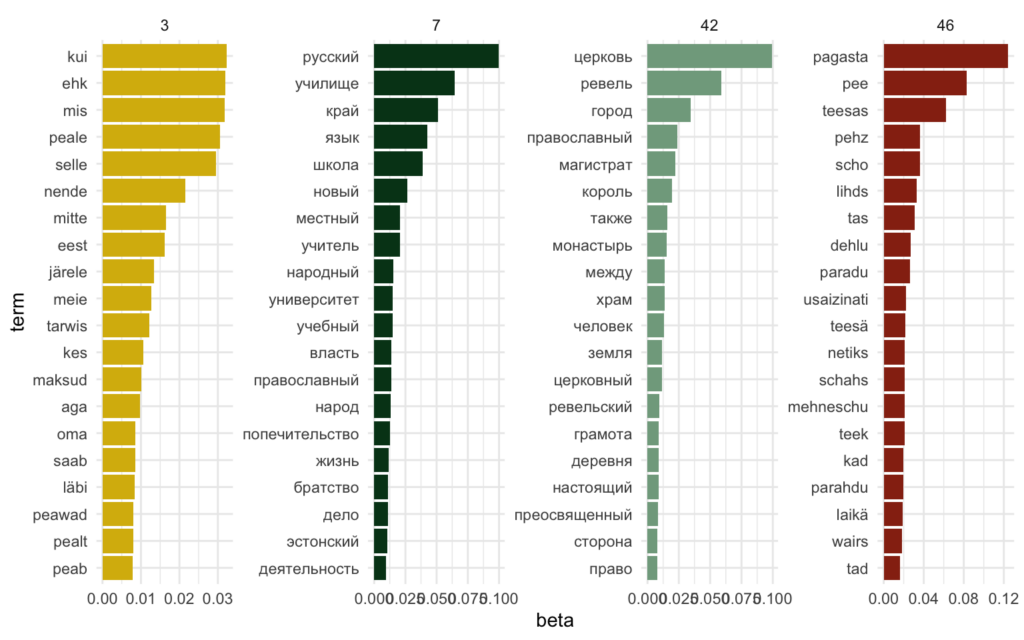
The model with 50 topics allows to take a closer look into the precise meaning of this ideologically rich topics which are the 7th and the 42nd. Topic 7 is most probably connected with the discussion on establishing Russian schools and other educational institutions in Estonian governorate (most probable words such as “Russian”, “school”, “language”, “teacher”, “national”, “educational”, “university”, as well as “orthodox”, “nation”, “brotherhood” and “Estonian” in the second ten most probable words). Topic 42 is more directly related with religion and orthodox curch in particular in Estonian governorate with the most probable words being “church”, “Revel”, “orthodox”, “monastery”, “temple”, etc.
The model with larger number of topics was also generally less mixing the langauges inside topics’ most probable words as well as it was able to gather in separate topics not only Russian, German and Estonian (topic 3), but also created a separate topic of Latvian words (46). The latter also reveals the fact that the first discussed 20 topics model had spotted Latvian language from the pages input (topic 2), however from the most probable words of this topic alone it would be less possible to recognize it as Latvian because most of the most probable words from the page-based model are in fact OCR-errors.
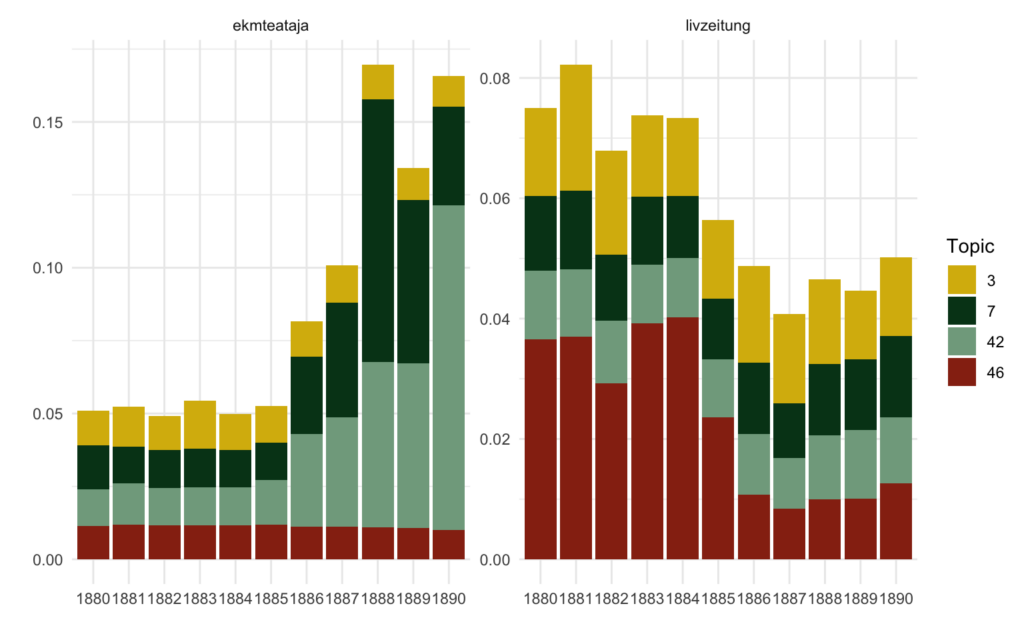
The distribution of topics over time shows two tendencies regarding these four topics. On the one hand, there is a decrease in the presence of “Latvian” topic (46) in the collection happened simultaniously with the start of Russification in the 1885; this does not however the same for a very small but stable proportion of “Estonian” topic (3). On the other hand, the ekmteataja shows a major growth of the ideology-related topics in the second half of the period where both sections discussing Russian schools and orthodox church are much more present after the change of the main language used in the newspaper. This change seems to be important in studying the discourse around the Russification in Estonia and might be studied more thoroughly in future. In addition, this level of precision in topic model interpretation in comparison with the results above seems to prove that section-based input is more reliable than the use of page-level data.
It is visible from both page- and section-based data that the topics of Russian education and orthodox church became very prominent in the Estonian governorate’s local newspapers but not visible in the Livonian one. One can suppose that there was probably another printed media in Livonian governorate to communicate these issues or that the Russification process was going differently in the two regions: the problem may be as well investigated further using both distant and close reading techniques.
Estonian Russian-language newspapers in 1917
Another period full of events is the year of two Russian revolutions. This is probably the only and last period of Russian-language printing in Estonia when several new newspapers appeared at the time to cover current events. New printed media were established as an answer to great changes in political life, as it was said, for example, in center-oriented newspaper The word of Revel” (“Ревельское слово”):
“‘The Word of Revel’ is being born during the hard times of timelessness, in the twilight of sinister uncertainties, in the time of a nightmare suffocation. This defines the conditions of the very existence of this new print media, of the new broadcaster of the word which is alive, fresh, truthful, brave, and, as far as possible, free. <…> These days we cannot keep silent: our position obliges us to speak about current needs, negative sides of the present times, which construct society’s evil <…>.” The Word of Revel. 1816. 24. detsember (the first issue)
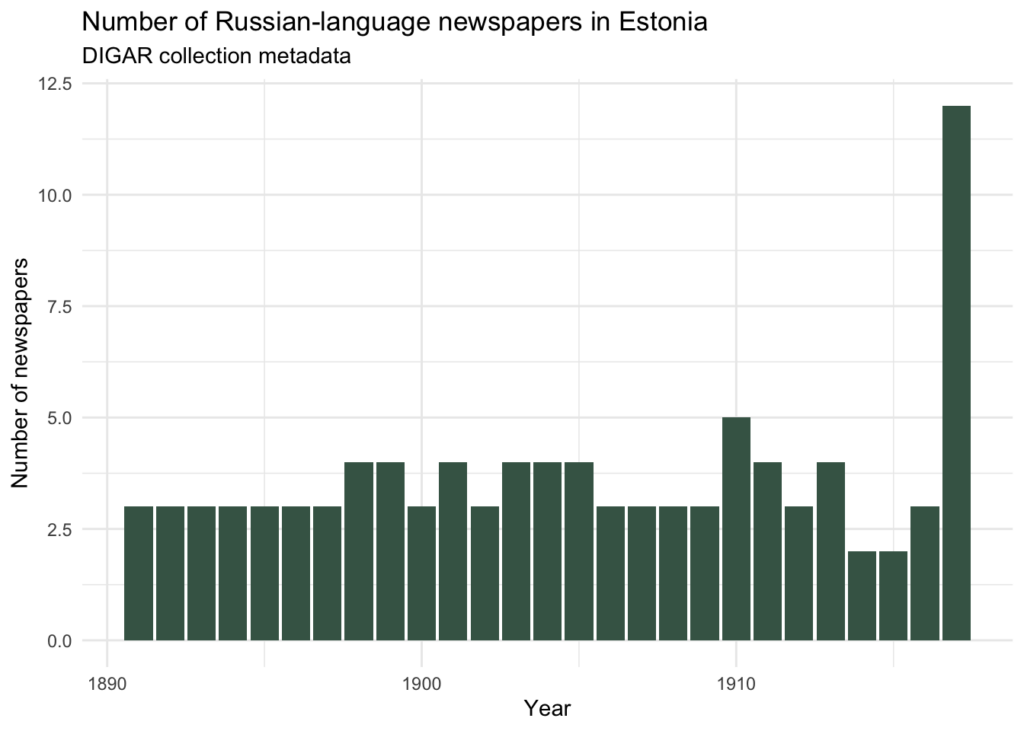
Below I would like to test a similar topic modeling approach to see if it can catch differences between some of the newspapers that appeared in 1917 and the well-established official newspaper of the Governorate of Estonia (the same discussed in the Part I). The hypothesis is that the newly appeared newspapers would speak about different topics than the old official one.
To test the hypothesis a topic model was built, taking into consideration six biggest newspapers of 1917. Roughly these newspapers may be characterized as
1. the oldest official one (The newspaper of the Governement of Estonia),
2. Old Revel local newspaper Revel News (“Ревельские известия”),
3. center-oriented new local Tallinn newspapers: The Word of Revel (“Ревельское слово”),
4. new revolution-inspired press of the social-democrats (“Известiя Ревельскаго совета рабочих и воинских депутатов”, “Утро правды”) and soldiers and sailors (“Свободное слово солдата и матроса”).
| First year of issue | Last year | Title |
|---|---|---|
| 1853 | 1917 | Эстляндские губернские ведомости |
| 1917 | 1918 | Известiя Ревельскаго совета рабочих и воинских депутатов : ежедневная газета = Tallinna Tööliste ja Sõjawäeliste Saadikute Nõukogu Teataja : päewaleht |
| 1917 | 1918 | Свободное слово солдата и матроса : политический и литературный орган |
| 1916 | 1919 | Ревельское слово : ежедневная общественно-политическая газета |
| 1893 | 1917 | Ревельские известия : газета местных интересов, литературная и политическая |
| 1917 | 1918 | Утро правды : орган Ревельского комитета Р.С.-Д.Р.П. |
The data includes 3228 pages from which were excluded stopwords and the words longer than 2 characters (resulting in 8174 unique words / lemmata). The LDA topic model is built for 20 topics which are in this case monolingual.
From the topic distribution on the timescale, the oldest official newspaper (ekmteataja) appears to be the most different from the others. It discusses local news in somewhat of archaic discourse: its most probable topic 20 refers to local issues such are “city” “Revel” “court”, etc., more or less in the same manner as in the 1880s; topics 7 and 17 appears to be more contemporary discussing “counsel”, “government”, “minister”[s], and “duty”, but it seems none of the other sources uses this vocabulary in the same way to speak about current events (the word “duty” is a particular relict of the tsarist Russia).
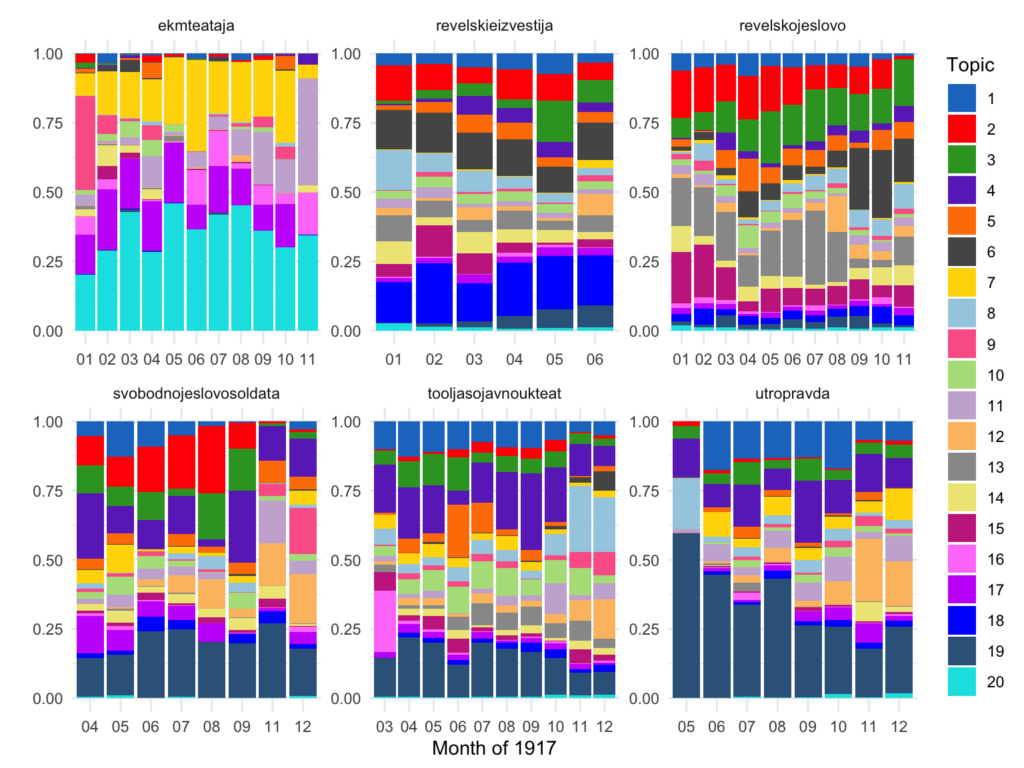
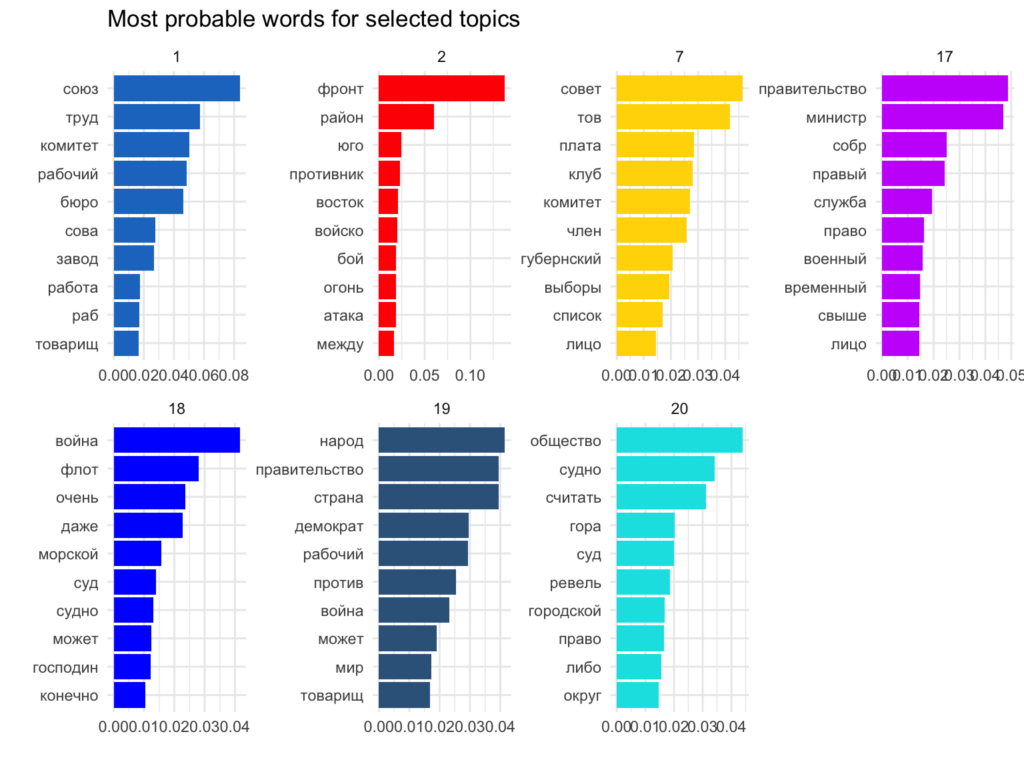
The left-wing The Morning of the Truth (“Утро правды”, utropravda label), Tallinna Tööliste ja Sõjawäeliste Saadikute Nõukogu Teataja (tooljasojavnoukteat) and The Free Word of Soldiers and Salors (“Свободное слово солдата и матроса”, svobodnojeslovosoldata) use another set of words to address political issues. for instance:
* topic 19 most probable words: “nation”, “democrat”, “working”, “against”, “comrade”;
* topic 1 unique to other topics words are: “union”, “labor”, “factory”, “work”;
The new media are also far more concerned about the course of the war and discuss more of the news from the front line (topic 2, the most probable words: “front”, “region”, “south-”, “enemy”) and sea battles (topic 18, the most probable words: “war”, “fleet”, “very”, “even”, “sea”, “court”, “vessel”).
As the gap between the official language of the empire and the actual political discourse was rising in the Russian Empire since the 1860s, this difference is clearly visible in the Estonian local newspapers as well. The political orientation of the newly created newspapers based on their vocabulary use might be an object of further investigation.
Cite the blog post:
Martynenko, Antonina. 2022. Imperialistic Russian discourse in the 1880s and 1917. Eesti Rahvusraamatukogu digilabori juhtumiuuringud. DOI 10.17605/OSF.IO/B3F8Y.
Data and code are available here: https://doi.org/10.17605/OSF.IO/B3F8Y.
The study has been made as part of the EKKD72 project "The usage possibilities of textual data in digital humanities case studies on the example of newspaper collections in Estonia (1850-2020)".
Eesti Rahvusraamatukogu
Tõnismägi 2, 10122 Tallinn
+372 630 7100
info@rara.ee
rara.ee